Difference between revisions of "Team:UESTC Software/Modeling.html"
| Line 83: | Line 83: | ||
<p>Finally,To get a more particular knowledge of changing trend. We made a diagram to illustrate the <b>relation</b> of minimal gene set with number of organisms and HNR.</p> | <p>Finally,To get a more particular knowledge of changing trend. We made a diagram to illustrate the <b>relation</b> of minimal gene set with number of organisms and HNR.</p> | ||
<p>We use the <b>least square method</b> to get the <b>fitting polynomial</b> for every lines in the figure 1.2(100 polynomials here). We choose the <b>3 order</b> polynomial. To get the 4 coefficients for the polynomial, we use the same method to get the <b>relation of coefficient with the HNR</b>. The 4 coefficients’ fitting polynomials are as follows:</p> | <p>We use the <b>least square method</b> to get the <b>fitting polynomial</b> for every lines in the figure 1.2(100 polynomials here). We choose the <b>3 order</b> polynomial. To get the 4 coefficients for the polynomial, we use the same method to get the <b>relation of coefficient with the HNR</b>. The 4 coefficients’ fitting polynomials are as follows:</p> | ||
| − | <img src="/wiki/images/thumb/6/63/Team-UESTC_Software_gsabcd.jpg/800px-Team-UESTC_Software_gsabcd.jpg"> | + | <img src="/wiki/images/thumb/6/63/Team-UESTC_Software_gsabcd.jpg/800px-Team-UESTC_Software_gsabcd.jpg.png"> |
<p>The polynomial for the relation of the minimal gene set with number of organisms and HNR is as follows:</p> | <p>The polynomial for the relation of the minimal gene set with number of organisms and HNR is as follows:</p> | ||
<img src="/wiki/images/c/cd/Team-UESTC_Software_gsz.jpg"> | <img src="/wiki/images/c/cd/Team-UESTC_Software_gsz.jpg"> | ||
Revision as of 09:36, 15 September 2015
Modeling&Validation
(Tools: php&Matlab)
Modeling
Overview
Modeling is one of the most important parts in our project. In the modeling, the data we used mainly from the CEG (Cluster of Essential Genes)1 data base.In the CEG, genes’ category were based on their corresponding KEGG(Kyoto Encyclopedia of Genes and Genomes) Orthology (KO) and COG2(Clusters of Orthologous Group) category and function descriptions.
Ubiquity-retaining strategy3 was first put up by Koonin .E V, we used half-retaining strategy to cover the shortage. Actually we use the 42% as the ratio not the half. Our modeling is to find it and prove it logically.
In the modeling, we use the knowledge of statistic. Find the relation of size of minimal-gene-set with number of organisms and HNR(Half Number Ratio). HNR is a ratio value that we use to replace the “half” in our strategy. Then we construct the 3d modeling for that.
Besides, to get the ideal value of HNR, we use the multivariable linear regression to get the fitting polynomial for the relation of OE rate with the HNR. From the polynomial, we find the appropriate HNR for our strategy, which has the highest OE rate and many other advantages compared with other HNR.Finally, we test our software’s calculating time: start as we input organisms until we get the output result.
We divide our modeling into 3 steps.
Step 1
Firstly, we randomly choose 4 organisms from the data base(totally 29 organisms) as the experiment no.1 and rechoose 5 organism as experiment no.2 until we have 28 organisms in experiment no.25(We choose 10 times for one experiment, then get the average of every data of it) . we observed the trend of the size of minimal-gene-set from experiment no.1~25, and noticed a decrease trend when using the ubiquity-retaining strategy(Koonin) while a stabilization trend when using the half-retaining strategy. Line chart as follow(Fig 1.1):
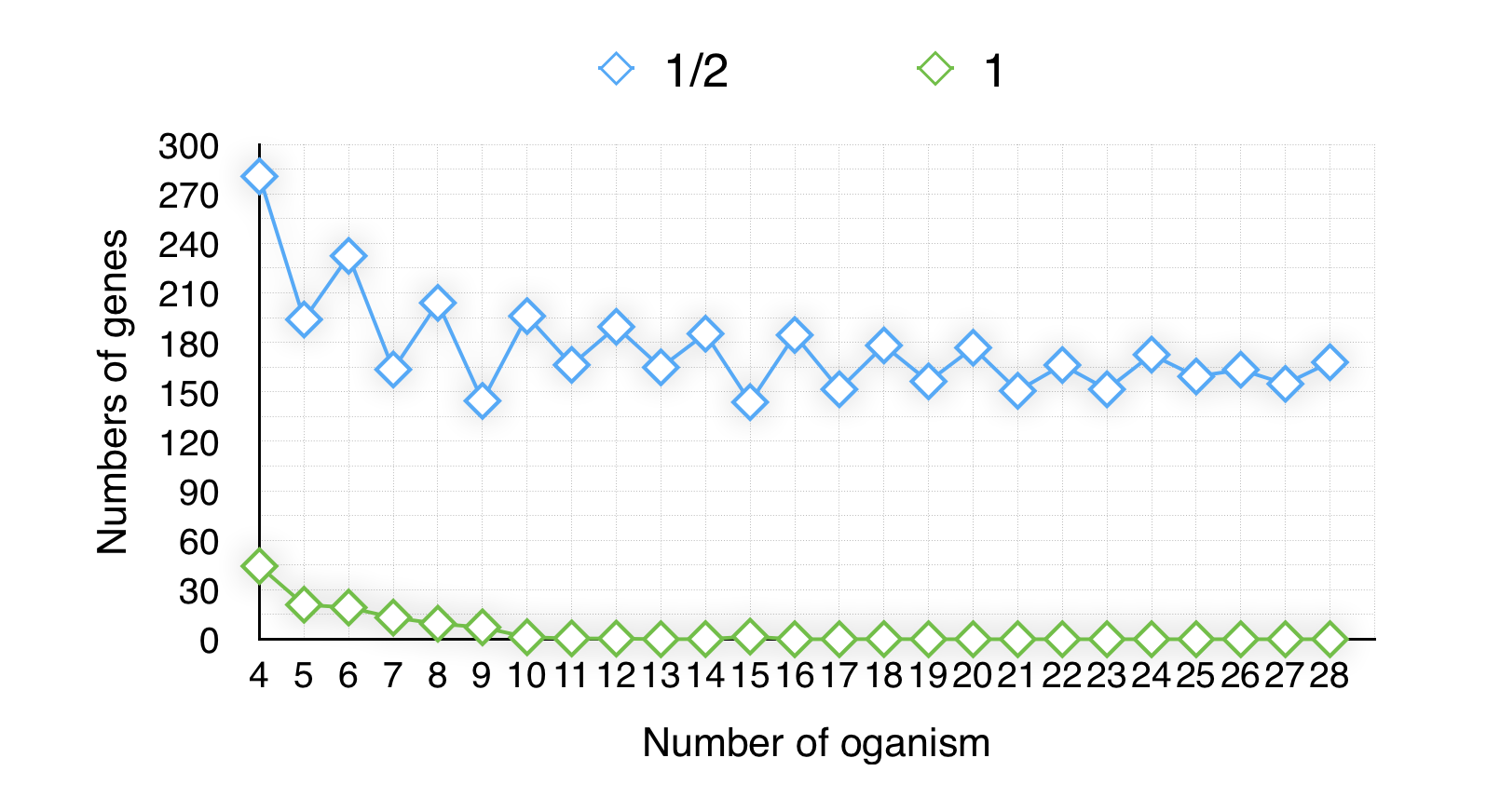
Obviously, the result of the half-retaining strategy seems more steady and more significant with the number of organisms’ increasing than the ubiquity-retaining strategy.
Secondly, to find the relationship between the HNR(Half Number Ratio) and the size of minimal-gene-set. We divide 100% into 100 groups (1%~100%). Now we have 100 groups and 25 experiments. Then we respectively get the experiment no.1~25’s size of minimal-gene-set in every group. And finally get line charts like Fig 1.2 and Fig 1.3(Cause there are too much data that we only list the 1/10,2/10~10/10’s results in Fig 1.2):
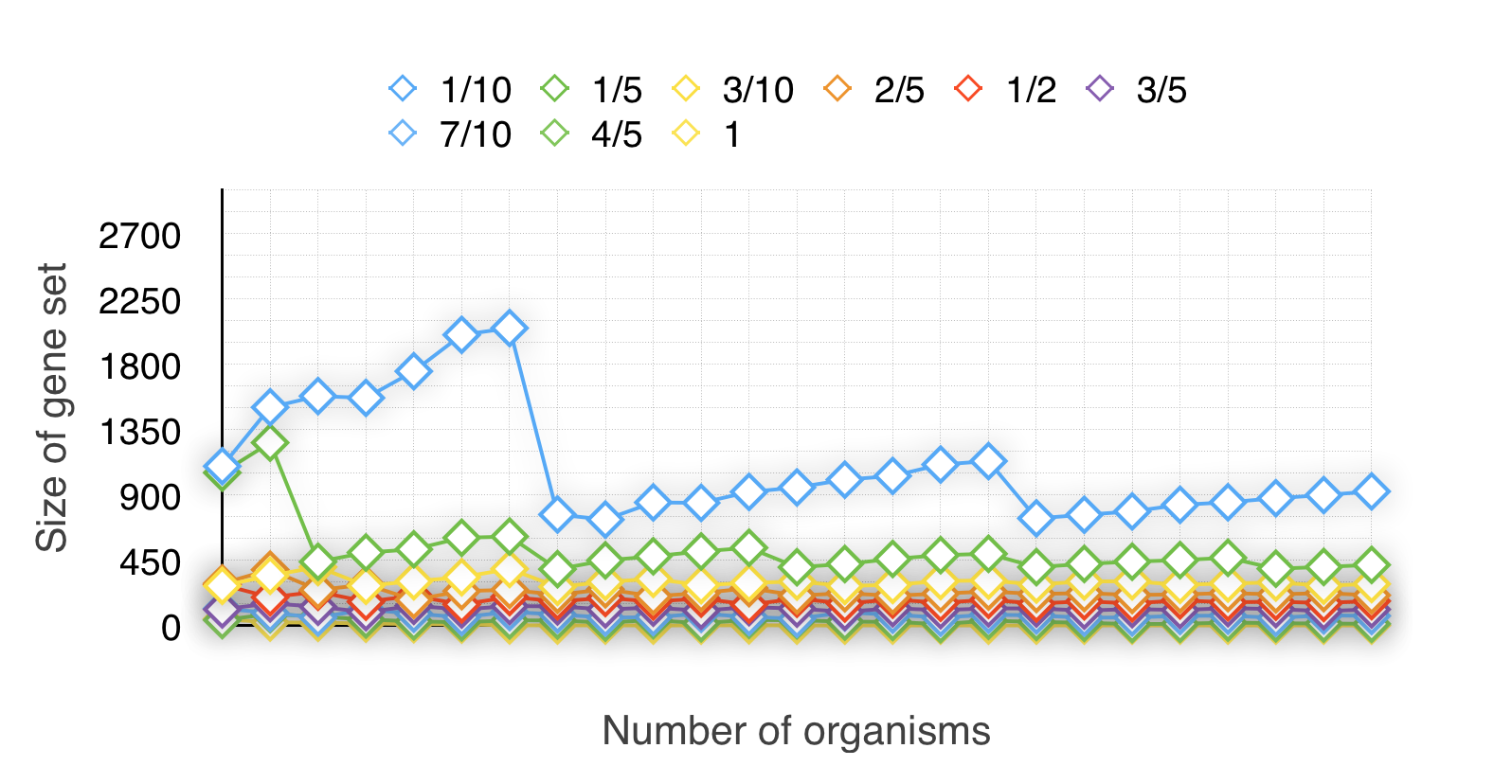
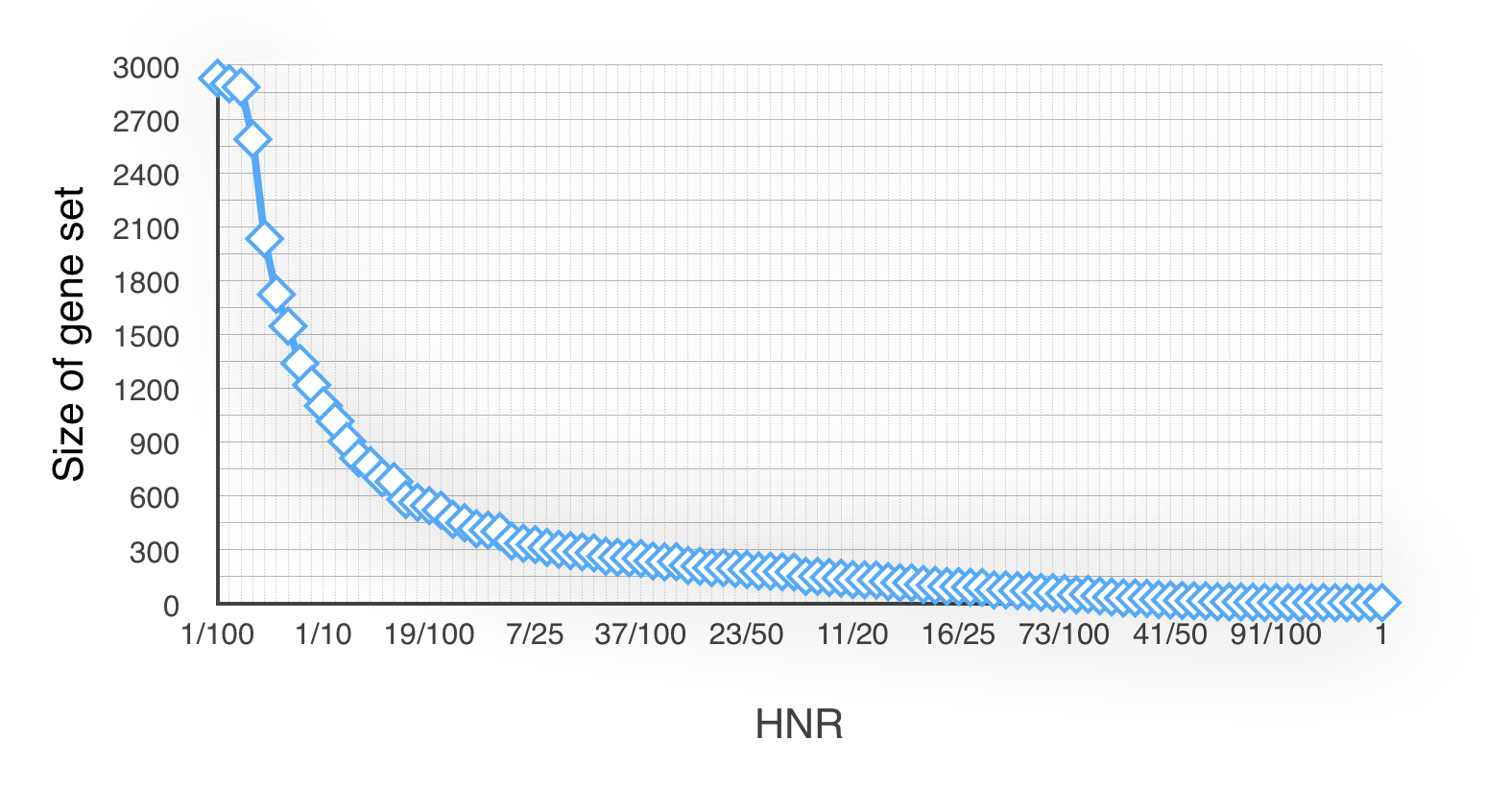
Our ideal size of minimal-gene-set is about 150~300. The conclusion is that the HNRs between interval [30/100~51/100] ’s size of minimal-gene-set are more close to the ideal amount.
Finally,To get a more particular knowledge of changing trend. We made a diagram to illustrate the relation of minimal gene set with number of organisms and HNR.
We use the least square method to get the fitting polynomial for every lines in the figure 1.2(100 polynomials here). We choose the 3 order polynomial. To get the 4 coefficients for the polynomial, we use the same method to get the relation of coefficient with the HNR. The 4 coefficients’ fitting polynomials are as follows:

The polynomial for the relation of the minimal gene set with number of organisms and HNR is as follows:
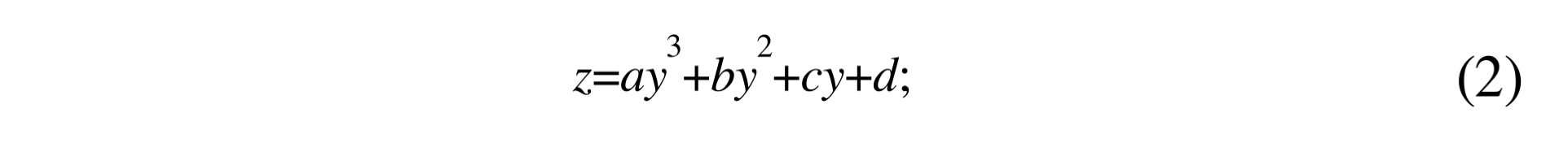
Now we have the polynomial to connect the relation of minimal gene set with number of organisms and HNR. The diagram is as follows:
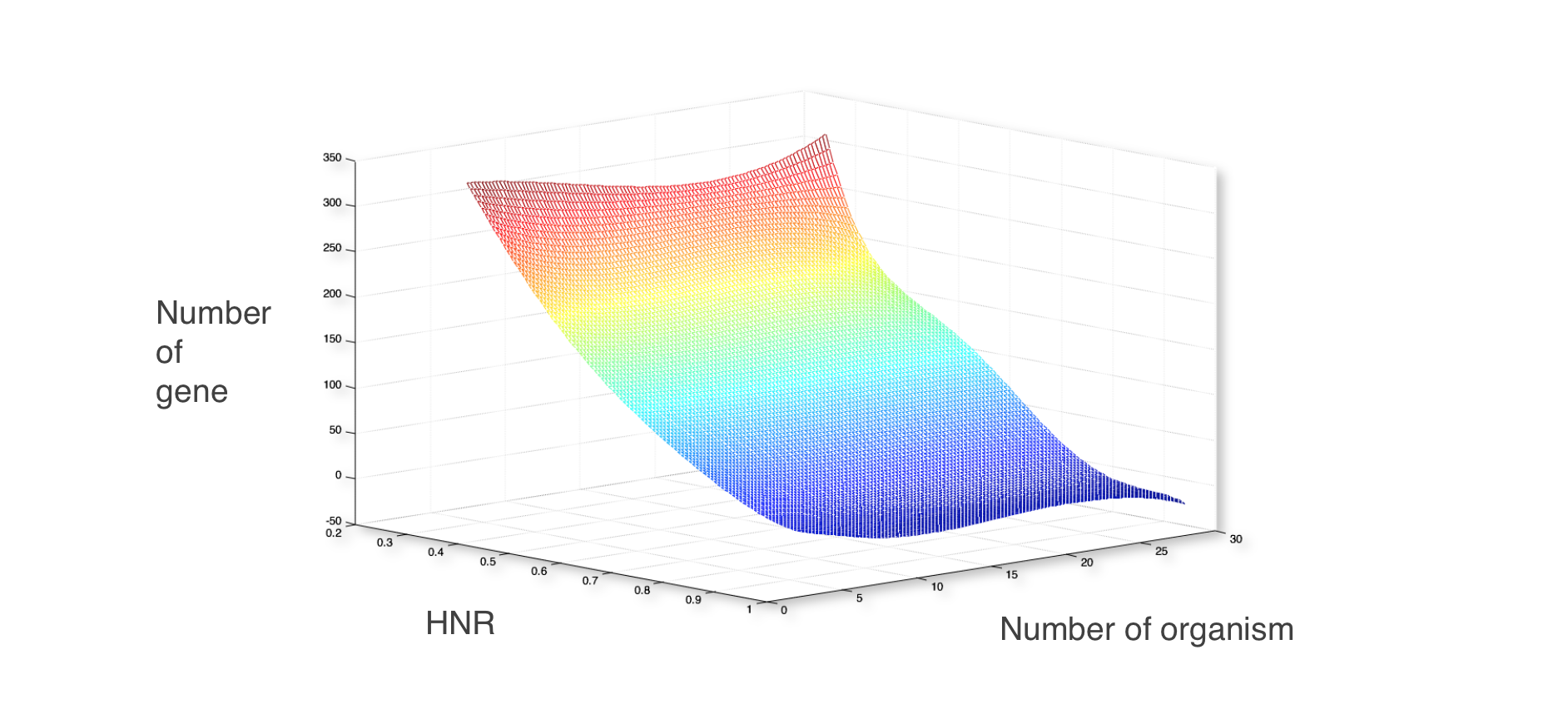
From diagram above, we found an area that have a stable gene number when organisms number changed. It means use these half number ratio can get a stable result of minimal gene set. But to find the most stable HNR for the “half” retaining strategy, let’s move to step 2.
Step 2
From the Step 1, we divided 100% into 100 groups (1%~100%). And we also have 25 experiments. Besides, before doing the experiments, we should define a new variable to measure whether the strategy is stable and effective. We call it OE rate( Overlapping Effective Rate). It’s calculated by this formula:
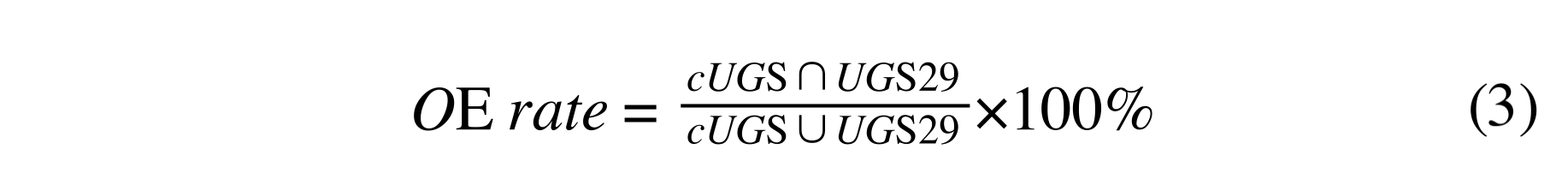
cUGS: the number of current experiment’s universal-gene-set-result
UGS29:the number of 29-organism-experiment’s universal-gene-set-result
This formula is to reduce the influence of the Gene’s amount. More OE rate means the strategy has a more sufficient result.
Now we have 100 groups and 25 experiments. Then we respectively calculate experiment no.1~25’s average of OE rate in every group. And finally get this line chart like Fig 2.1:
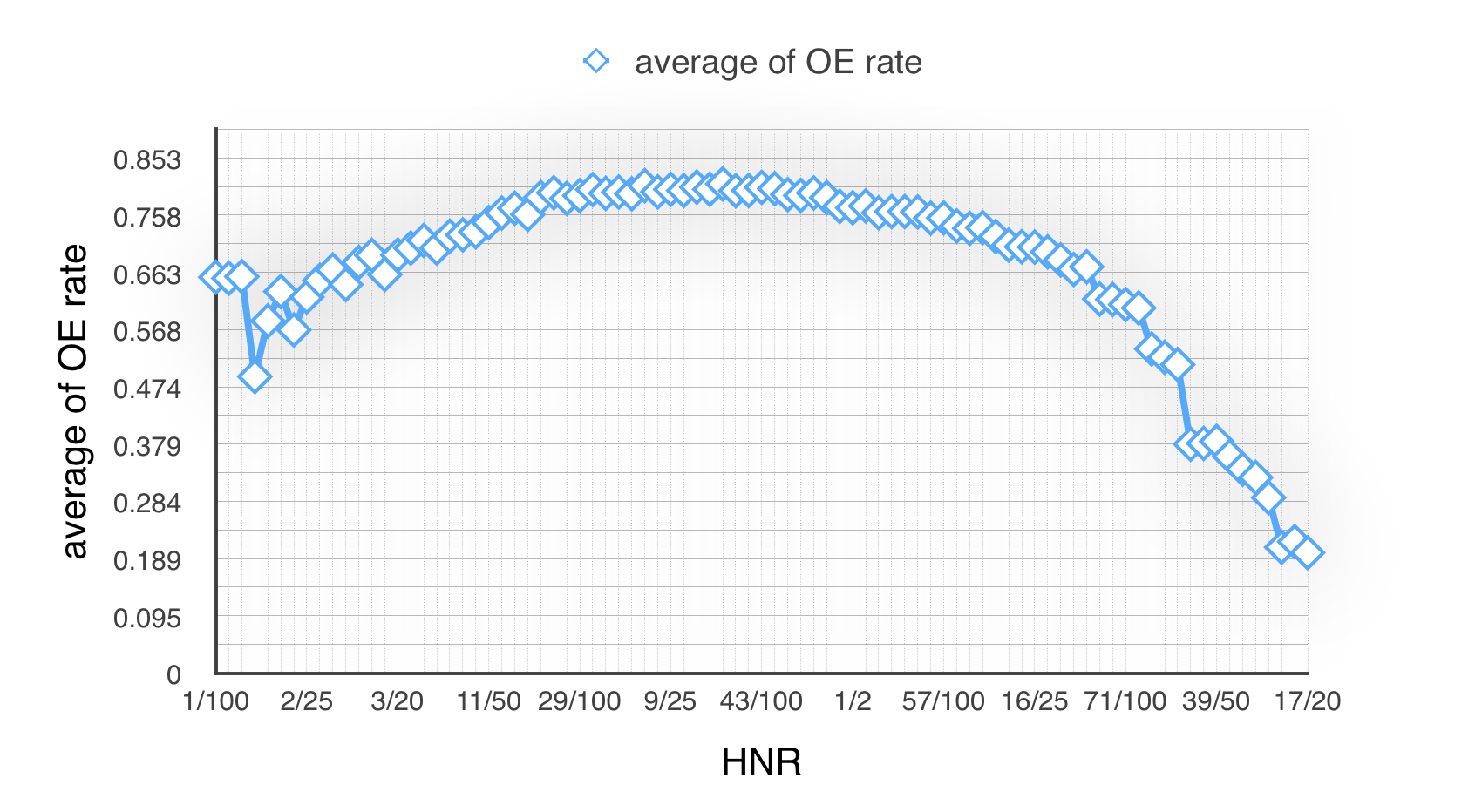
Obviously, we could find there are several groups has an ideal result, and also some unexpected results.
Next, we calculate experiment no.1~25’s variance in every group. Line chart as follow:
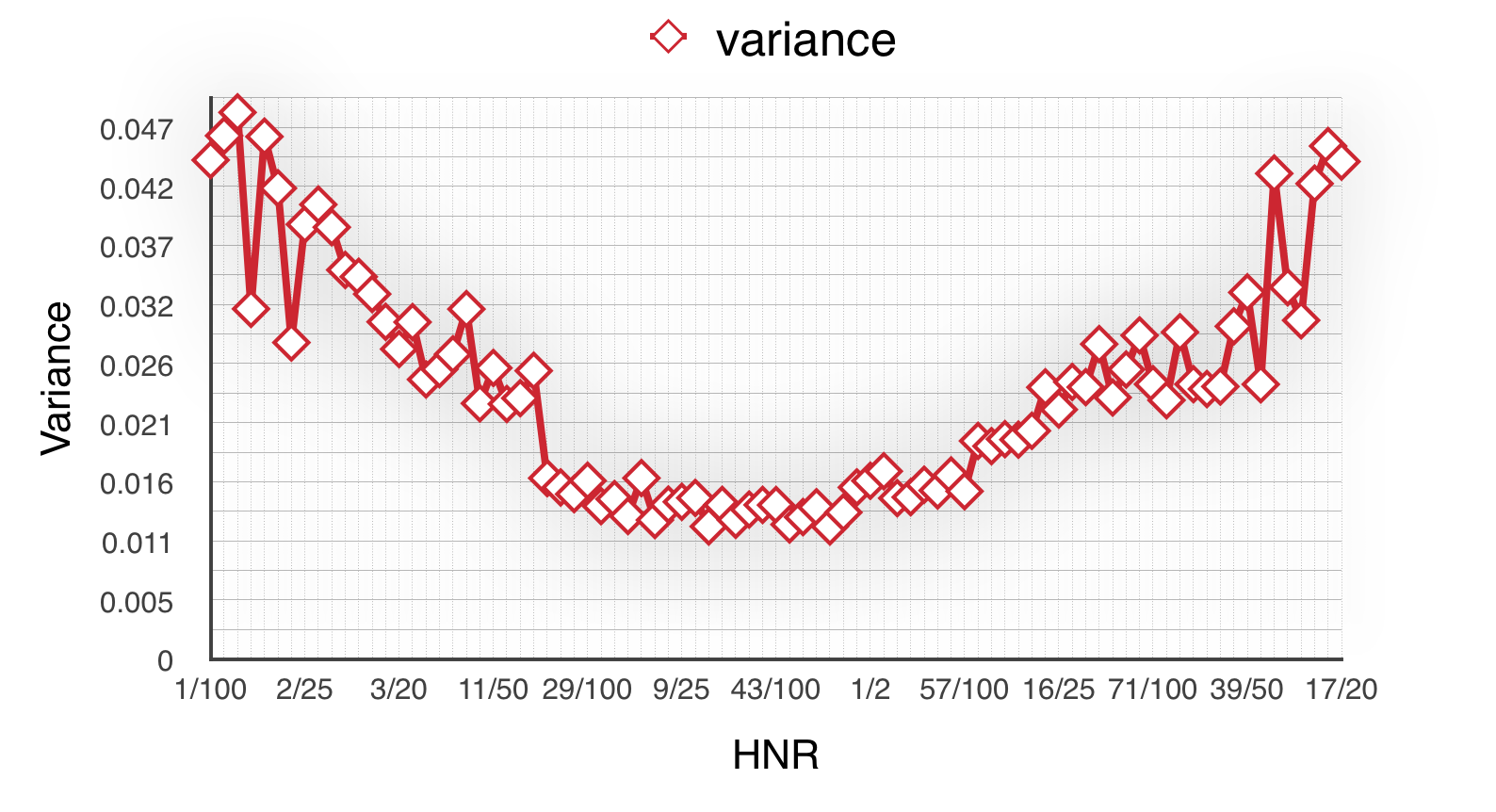
From the Fig 2.2, comparing the variances we could easily find the groups between 26/100~61/100’s variances are less than others which means strategy in this interval is more steady. It’s fortunate that we nearly get the same conclusion with the best interval mentioned in step 1.
Fortunately, we got a pretty results. We use the least square method to get the fitting polynomial. The new curve graph like this:

The polynomial is as follow:

After comparing the order of polynomial,we choose the 4 order polynomial. The correlation coefficient is 0.9703. According to the list. The polynomial is 97% to be accepted.
Next we calculate the maximization point as our ideal HNR (42%). That is how we define the ratio value of the retaining strategy.
Step 3
In step 3, we try to get the MCCAP’s calculating time. We test the experiment no.1~no.25(4 organisms ~ 28 organisms like step 1&2) in our 42% ratio retaining method to get the running time.
The bar chart is as follows:
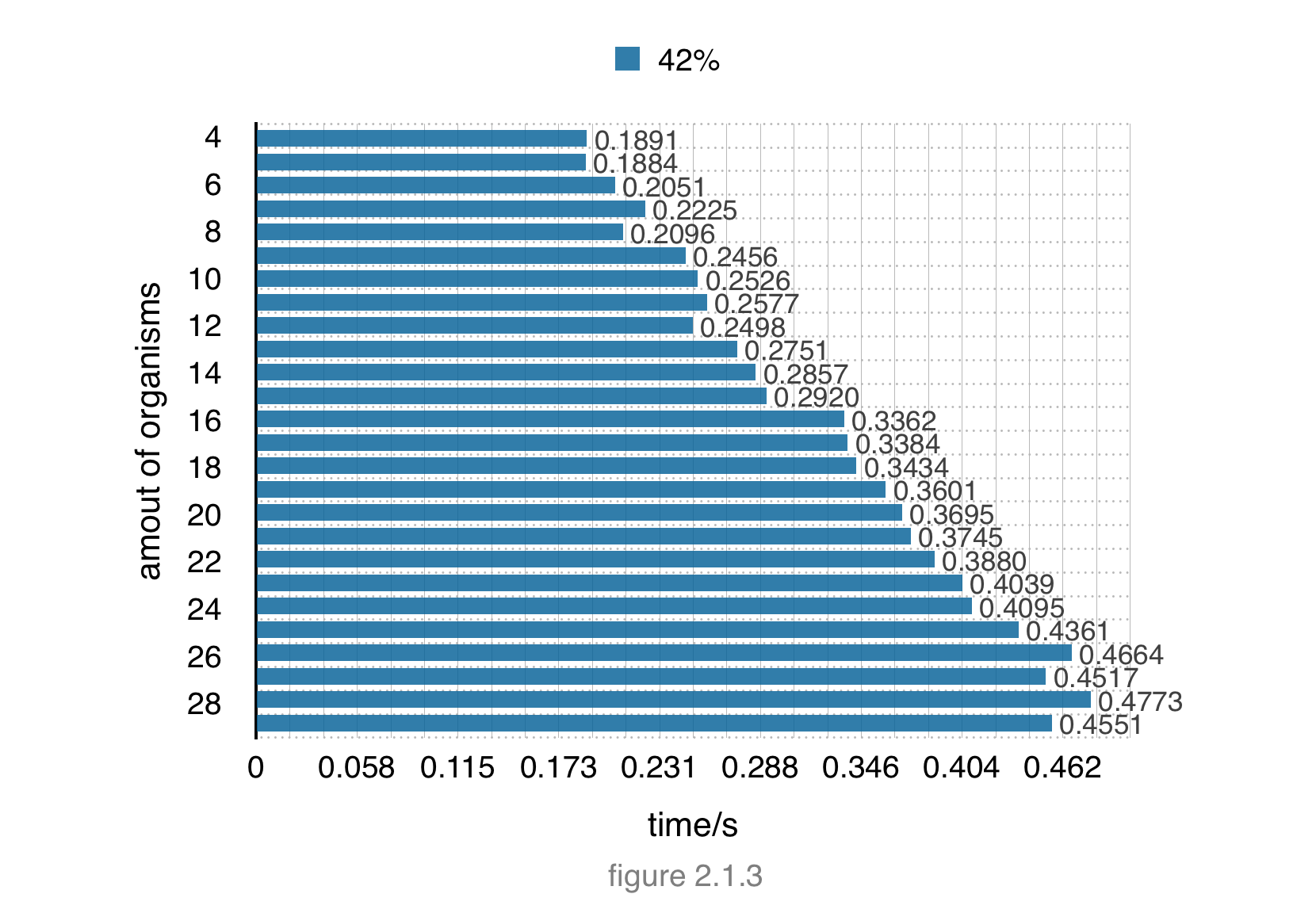
From the bar chart , as the increasing number of organisms, the running time increase gradually. But when we use all of the organisms from CEG data base. We still only spend less than 0.5s to get the results. The efficiency of MCCAP’s calculating can be accepted, and MCCAP did well in this aspect.
Validation
Step 1
We pick a organism from the 29 organisms(from no.1~no.29) one by one as 29 experiments . Then respectively use the remaining 28 organisms to screen the minimal gene set again and compare the results with the completed(29 organisms) one to get the overlapRatio.
The line chart is as follow:

The variance of the overlapRatio is 0.000479
From the line chart and the variance, we could easily get a conclusion that all the experiments’ overlapRatios are more than 90% and vary slightly, which means our strategy is accurate and stable.
Step 2
Then let’s move to step 2. In step 1 we proved that our strategy is stable and accurate. Next, we compare the result with other two results(Gil, Mushegian&Koonin) which has got the minimal gene set by using other methods to prove our method is reliable and significant.

From the flow charts, unlike these two groups we have fewer genes in our minimal gene set, and have a higher overlap numbers for having 190 same genes with the Gil, and 156 genes with the Mushegian&Koonin’s result.Only 5 genes are different from other two groups. After this step, it’s obvious that our result is reliable and stable.
Reference
1.Yuan-nong Ye, Zhi-gang hua, Jian Huang, Nini Rao and Feng-biao Guo*: CEG: a database of essential gene clusters. BMC Genomics 2013
2.Roman L.Tatusov, Michael Y. Galperin, Darren A. Natale and Eugene V. Koonin*: The COG database: a tool for genome-scale analysis of protein functions and evolution
3.Mushegian AR, Koonin EV:A minimal gene set for cellular life derived by comparison of complete bacterial genomes. Proc Natl Acad Sci U S A 93, 10268-10273 (1996).