Difference between revisions of "Team:Oxford/Modeling/Tutorial"
| Line 3: | Line 3: | ||
<html> | <html> | ||
<div class="container-fluid page-heading" style="background-image: url(https://static.igem.org/mediawiki/2015/6/6d/Ox_modelling_will_poster.png)"> | <div class="container-fluid page-heading" style="background-image: url(https://static.igem.org/mediawiki/2015/6/6d/Ox_modelling_will_poster.png)"> | ||
| − | <h3> | + | <h3>Modeling Tutorials</h3> |
</div> | </div> | ||
<div class="container-fluid"> | <div class="container-fluid"> | ||
| Line 12: | Line 12: | ||
<h2>Introduction</h2> | <h2>Introduction</h2> | ||
<p> | <p> | ||
| − | On this page we aim to explain the concepts and methodology behind the <a class="definition" title="model" data-content="A simplified or idealised description of a system or process, usually mathematical, that can be used to predict how it will behave.">model</a>ling we have done in our project. We hope this will make our | + | On this page we aim to explain the concepts and methodology behind the <a class="definition" title="model" data-content="A simplified or idealised description of a system or process, usually mathematical, that can be used to predict how it will behave.">model</a>ling we have done in our project. We hope this will make our modeling section more accessible for all members of the iGEM community. |
</p> | </p> | ||
</div> | </div> | ||
Revision as of 15:12, 18 September 2015
Modeling Tutorials
Introduction
On this page we aim to explain the concepts and methodology behind the modelling we have done in our project. We hope this will make our modeling section more accessible for all members of the iGEM community.
Gene Expression Networks
Mass Action
Our goal is to model a system of reactions such as the reversible reaction
\[A \mathrel{\mathop{\rightleftharpoons}^{\mathrm{k_{+}}}_{\mathrm{k_{-}}}} B\]Where \(A\) and \(B\) are our two species and \(k_{+}\) and \(k_{-}\) will be determined shortly. To do this, we make the intuitive assumption that the rate at which something reacts is proportional to how much of it we've got. That is, the rate of change of \(B\) with time is
\[\dfrac{dB}{dt}=k_{+}A\]where \(k_{+}\) is simply a proportionality constant. This assumption is called the law of mass action. This of course is not the complete picture, as we forgot to include the fact that \(B\) can react back to form \(A\). So the complete system of equations to solve is
\[\dfrac{dA}{dt}=k_{-}B-k_{+}A\] \[\dfrac{dB}{dt}=k_{+}A-k_{-}B\]At this point, you can type these into your favourite computing program and solve them.
Michaelis-Menten Kinetics
It is possible to formulate a rate law that describes enzyme-catalysed reactions, this is known as Michaelis-Menten kinetics. In order to derive this rate law we will look at a generalised system of chemical events detailed below:
\[S + E\mathop{\rightleftharpoons}C_{1}\mathop{\rightleftharpoons}C_{2}\mathop{\rightleftharpoons}P + E\]In this system \(S\) represents our substrate, \(E\) our enzyme, \(C_{1}\) our enzyme-substrate complex, \(C_{2}\) our enzyme-product complex, and \(P\) our product.
Initially we will make two simplifications. Firstly, we will combine \(C_{1}\) and C2 into a single complex, \(C\), as we will assume that the time-scale of the conversion \(C_{1}\mathop{\rightleftharpoons}C_{2}\) is much faster than that of the association and dissociation events. Secondly, we will assume that the product never binds with the free enzyme. These two assumptions lead to the simplified network:
\[S + E\mathrel{\mathop{\rightleftharpoons}^{k_{1}}_{k_{-1}}}C\mathop{\rightarrow}^{k_{2}}P + E\]Using the laws of mass action (detailed above) we arrive at the following differential equation model:
\[\dfrac{d}{dt}s(t)=-k_{1}s(t)e(t) + k_{-1}c(t)\] \[\dfrac{d}{dt}e(t)=k_{-1}c(t) - k_{1}s(t)e(t) + k_{2}c(t)\] \[\dfrac{d}{dt}c(t)=-k_{-1}c(t) + k_{1}s(t)e(t) - k_{2}c(t)\] \[\dfrac{d}{dt}p(t) = k_{2}c(t)\]Concentrations are denoted as the lowercase letter eg the concentration of \(S\) is given by \(s\).
You may have spotted that the enzyme is not consumed in this series of reactions. Therefore the total amount of enzyme remains constant. We reflect this in the expression \(e_{T}=e+c\). We can now use this expression to eliminate \(e(t)\) from our model, leaving:
\[\dfrac{d}{dt}s(t)=-k_{1}s(t)(e_{T}-c(t)) + k_{-1}c(t)\] \[\dfrac{d}{dt}c(t)=-k_{-1}c(t) + k_{1}s(t)(e_{T}-c(t)) - k_{2}c(t)\] \[\dfrac{d}{dt}p(t) = k_{2}c(t)\]We have one further simplification to make. This is the rapid equilibrium approximation, by which we assume that equilibrium between \(s+e\) and \(c\) on a much faster time scale than the reaction of \(c\) to \(p\). With this approximation we can write the following equation:
\[0=-k_{-1}c(t) + k_{1}s(t)(e_{T}-c(t)) - k_{2}c(t)\]Leading to:
\[c^{*}(t)= \dfrac{k_{1}s(t)e_{T}}{k_{-1} + k_{2} + k_{1}s(t)}\]Now we can see that \(c\) is no longer an independent variable, but instead tracks the other variables. This can be referred to as \(c\) being in quasi-steady state. By including this new expression into our model we are left with:
\[\dfrac{d}{dt}s(t) = -\dfrac{k_{2}k_{1}s(t)e_{T}}{k_{-1} + k_{2} + k_{1}s(t)}\] \[\dfrac{d}{dt}p(t) = \dfrac{k_{2}k_{1}s(t)e_{T}}{k_{-1} + k_{2} + k_{1}s(t)}\]With this we have an expression describing our enzyme catalysed system in the form of a single reaction. The rate of this reaction is known as a Michaelis-Menten rate law. By defining \(K_{max}=k_{2}e_{T}\) and \(K_{half}=\dfrac{k_{-1}+k_{2}}{k_{1}}\) we can express in the more familiar form:
\[rate \: of \: S \mathop{\rightarrow} P = K_{max}\dfrac{s}{K_{half} + s}\]It is worth noting that there are a number of ways to derive this form, each involving different approximations. These methods may lead to the constants \(K_{max}\) and \(K_{half}\) being defined differently.
Stochastic
The simplest way to add an element of 'randomness' into an equation is to add a random term into the differential equation. This turns it into a stochastic differential equation, such as:
\[\dfrac{dx}{dt}=c+r\]
which determines the evolution of a particle travelling at a speed \(c\), with a random number \(r\) added into the mix just for fun. We choose \(r\) to be normally distributed with a mean value of 0 and a variance of, say, 1. We evaluate the position of the particle at multiple timesteps (with some small time \(dt\) separating them) and plot our solution in the Figure below.
We can do better than this when dealing with systems such as our example in the previous section. We use the Gillespie algorithm to find:
- The time taken between reactions
- The reaction that took place in that time.
as neither of these could be determined by our initial method [2, 4].

1) To find the time taken, we make an assumption about the form of the probability distribution that the time between reactions holds. It makes sense to think of it as a falling exponential, such that reactions more often happen quickly rather than slowly, and that the more probable a reaction is, the shorter the time between subsequent reactions. This naturally leads to the form
\[P(t)=e^{-\alpha_{0}t}\]where \(P(t)\) is the probability of any reaction occuring in time \(t\), and \(\alpha_{0}\) tells us something about the likelihood of the reaction. We plot this in the Figure. In fact we call \(\alpha_{0}\) the sum of the propensities \(\alpha_{i}\) (where the dummy variable \(i\) runs from 1 to the number of possible reactions, \(N\), that could occur). In the case of our example system, the propensity for the reaction \(A\) to \(B\) would be \(k_{+}A\) and the propensity for the reaction \(B\) to \(A\) is \(k_{-}B\) so in this case \(\alpha_{0}=k_{+}A+k_{-}B\).
To decide the time it took for a reaction to occur, we sample a random number \(r_{1}\) in the range [0,1] and stick that number on the y axis of the graph. We read off from our graph a corresponding time and we're done - we now know when the next reaction took place.
2) To decide which reaction took place, we need the probabilities of each reaction occuring being proportional to the ratio of their propensities. We split up the domain of 0 to 1 into the normalised ratios of the propensities of our problem, recalling the propensities we calculated. We could have, in this case, selected the backwards reaction B to A. We can generalise this to the form given in the Gillespie Algorithm above.

Diffusion
In this section we will derive some of the equations used in the Delivery Section.
Diffusion out of our Beads
In order to find the convection mass transfer coefficient, \(K_m\) of our beads in water we needed derive a theoretical curve to fit our experimental data to. To do this, we made a number of approximations. Our beads are assumed to be spherical and of the diameter. We also used a lumped capacitance model, in which the concentration of substance is assumed to be uniform within the bead. We will also make use of the equivalence of heat and mass transfer.
Our derivation starts from Newton's law of cooling
\[Q = hA\Delta T\]Where \(Q\) is the flow of energy, \(h\) is the convection coefficient, and \(\Delta T\) is the difference in temperature accross the boundary. Or rather its mass equivalent
\[\dot{m}=K_{m}A_{b}\left(c_{b}-c_{f}\right)\]Where the mass flow rate, \(\dot{m}\), across a boundary is driven by the concentration difference across it. In our case the concentration difference is between the concentration of particles, \(c_f\) in the fluid and the beads, \(c_b\). Using the relationship
\[\dot{m}=V_{f}\dot{c_{f}}=-V_{b}\dot{c_{b}}\]With \(V_f\) and \(c_f\) as the concentration and volume of the fluid surrounding the beads, as well as \(A\), \(V_b\) and \(c_b\) representing the total area, volume and concentration of the beads themselves. We arrive at
\[\dot{c_{b}}=-\dfrac{V_{f}}{V_{b}}\dot{c_{f}}\quad c_{b}=c_{bo}-\dfrac{V_{f}}{V_{b}}c_{f}\]In this \(c_{b0}\) is the initial concentration of the beads. By substituting this into the mass equivalent of Newton's law of cooling we arrive at the expression
\[V_{f}\dot{c_{f}}=K_{m}A_{b}\left(c_{bo}-\left(1+\dfrac{V_{f}}{V_{b}}\right)c_{f}\right)\]This expression can be rearranged and integrated to with respect to time to give
\[c_{f}=\dfrac{c_{bo}}{\left(1+\frac{V_{f}}{V_{b}}\right)}-\dfrac{V_{f}}{K_{m}A_{b}\left(1+\frac{V_{f}}{V_{b}}\right)}\exp\left(-\dfrac{K_{m}A_{b}\left(1+\frac{V_{f}}{V_{b}}\right)\left(t+k\right)}{V_{f}}\right)\]where \(k\) constant that comes from integration.
At \(t=0\) \(c_f=0\), leaving us with
\[\dfrac{c_{bo}}{\left(1+\frac{V_{f}}{V_{b}}\right)}=\dfrac{V_{f}}{K_{m}A_{b}\left(1+\frac{V_{f}}{V_{b}}\right)}\exp\left(-\dfrac{K_{m}A_{b}\left(1+\frac{V_{f}}{V_{b}}\right)k}{V_{f}}\right)\]resulting in
\[k=-\dfrac{V_{f}}{K_{m}A_{b}\left(1+\frac{V_{f}}{V_{b}}\right)}\ln\left(\dfrac{K_{m}A_{b}c_{bo}}{V_{f}}\right)\]and therefore
\[c_{f}=\dfrac{c_{bo}}{1+\frac{V_{f}}{V_{b}}}\left(1-\exp\left(-\dfrac{K_{m}A_{b}\left(1+\frac{V_{f}}{V_{b}}\right)}{V_{f}}t\right)\right)\]This shows how the concentration of fluid varies over time when there is a constant volume of fluid surrounding the beads. However, in the experiment, 1ml of water was removed every 10 minutes. We account for this by taking \(V_f=V_{fo}-\dfrac{1\times10^{-6}}{10}\). Where volumes are given in \(m^3\), time is in minutes and \(V_fo\) is the initial volume of the fluid surrounding the beads.
Now we have derived the final expression, have a look at how this result was fitted to the experimental data to determine the value of \(K_m\) here.
Mass Exchanger
In our analysis of the use of beads in a mass exchange system we used the expression
\[J = K_mA\dfrac{c_{fo}-c_{fi}}{\ln\left(\dfrac{c_{B}-c_{fi}}{c_{B}-c_{fo}}\right)}\]but where did this come from?
For this derivation we need to take a look at the mass flow out of the beads across a differential area, \(dA\). To help visulise the system below is a diagram showing how the conentration of proteins varies through the mass exchanger.
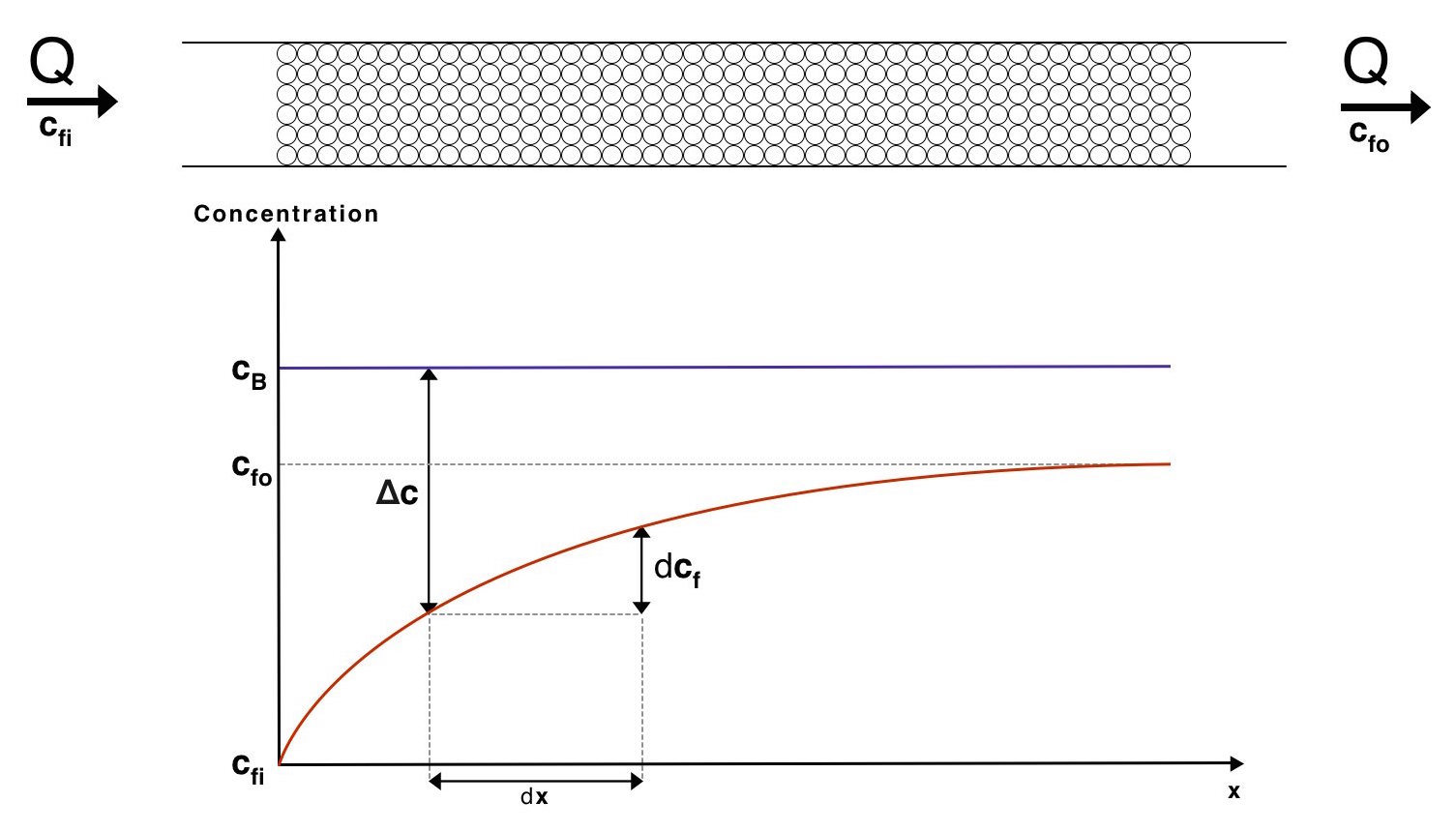
The mass flow rate across a differential area, \(dJ\) can be expressed as
\[dJ=K_{m}\left(c_{B}-c_{f}\right)dA\]This expression comes from the mass equivalent of Newton's law of cooling. We may use the relationship
\[dJ=Qdc_{f}\]Where \(Q\) is the volume flow rate of water through the mass exchanger. By combining these 2 relationships we arrive at
\[d\Delta c=-\dfrac{dJ}{Q}=\dfrac{-K_{m}\left(\Delta c\right)dA}{Q}\] \[d\Delta c=\dfrac{-K_{m}\left(\Delta c\right)dA}{Q}\]In this expression \(\Delta c=c_b-c_f\) at a distance \(x\) from the start of the mass exchanger. Rearranging and integrating leads to
\[\ln\left(\dfrac{\Delta c_{i}}{\Delta c_{o}}\right)=\dfrac{K_{m}}{Q}A\]Where \(\Delta c_{i}\) and \(\Delta c_{o}\) are the concentration differences at the inlet and outlet of the mass exchanger respectively. Thus \(\Delta c_{i} = c_B - c_{fi}\) and \(\Delta c_{o} = c_B - c_{fo}\).
The total mass flow, \(J\), can also be expressed as \(J=Q\left(c_{fo}-c_{fi}\right)\). Substituting this into the previous expression gives us
\[\ln\left(\dfrac{\Delta c_{i}}{\Delta c_{o}}\right)=\dfrac{K_{m}A\left(c_{fo}-c_{fi}\right)}{J}\]Which can be rearranged into the form
\[J=K_{m}A\dfrac{\left(c_{fo}-c_{fi}\right)}{\ln\left(\dfrac{c_{B}-c_{fi}}{c_{B}-c_{fo}}\right)}\]Comparing this to the form of the mass equivalent of Newton's law of cooling, \(J = K_mA\Delta c\), we see that we have derived an effective average concentration difference across the entire mass exchanger. This is known as the log mean concentration difference. We used this result to determine an estimate for the total exchange area required for our system, here.