Team:UESTC Software/Design
<!doctype html>
Design
Photo From © PEXELS
1. A reliable source of data
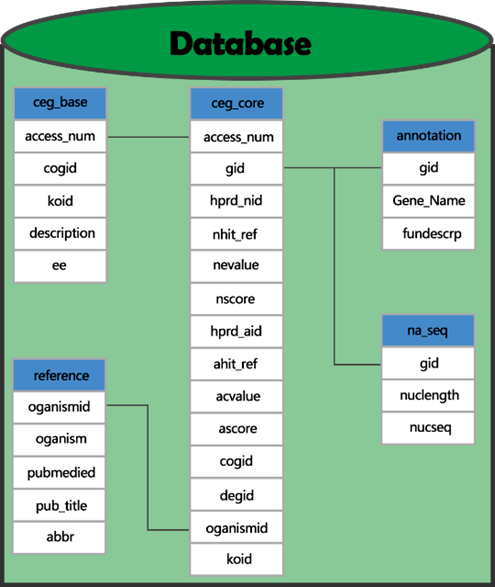
To deal with the data problem, we derived data of experimentally-determined essential genes from CEG database[1]. CEG(Cluster of Essential Gene) is a database which contains clusters orthologous essential genes. A notable feature of CEG is it deposits essential genes in orthologous groups rather than as single gene. There are seven tables in CEG database, and we used five of them selectively according to demand. Including ceg_core, which contains the information of each essential gene; ceg_base, which contains information of each gene cluster. And other three tables are reference, annotation and nucleic acid sequences.
We know upgrading is a key influence factor of the Product Life Cycle, and this is also our key consideration. The data of MCCAP will be constantly improving with updating of CEG, and reference species of it has increased from 16 to 29.
2. Determining the minimal gene set
The first and most important step of building a minimal artificial cell is determining the minimal gene set (minimal genome). Our method of solving this key task is the half retaining strategy. It is quite simple but effective. The implementer of the half-retaining strategy, MCCAP, achieves good results.
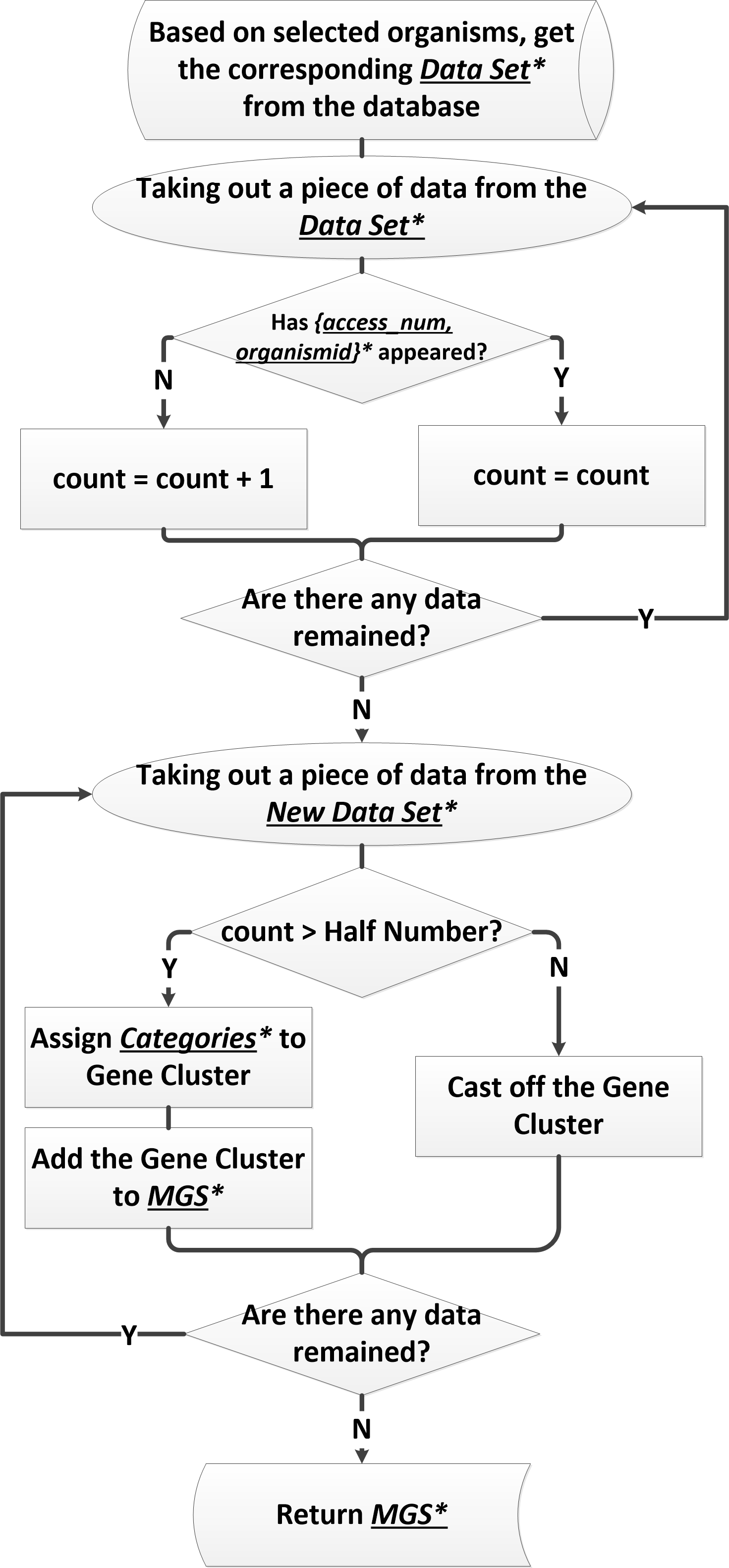
However, what exactly is the half retaining strategy?
Our half retaining strategy is basically one kind of Comparative Genomics Approach but it is further improved by starting with essential gene data determined by inactivation experiments. Firstly, we classify genes with the same function in different species into one category, named gene cluster. Secondly, we calculate the size of each gene cluster. Size means the number of species which contain the genes in this cluster. Finally, we put genes, whose size is no less than the half number (HN) together as the minimal gene set. For example, when there are 15 species, HN will be 8 according to our definition. So, if the size of a gene cluster is equal or more than 8, it will be added to the minimal gene set. In practice, we optimize the retaining ratio from the nominal half number to obtain more stable result.
And what is difference between the half retaining strategy and traditional method?
Contrast with the traditional comparative genomics method, it has two advantages as follow:
1. Traditional method is using comparative genomic approach to find ubiquitous genes from two completely sequenced small bacterial genomes. As we know in introduction, it will lose some genes when essential cellular function is performed by unrelated proteins that show no sequence similarities to each other in different organisms. However, half retaining strategy can get a stable result of minimal gene set, for it is based on plenty of reference species and an ideal retaining ratio.
2. Half retaining strategy uses experimentally-determined essential genes which are specific to organisms. Differ from traditional method, which is based on the whole genome, Half retaining strategy has lower false positive results.
MCCAP implements the half retaining strategy perfectly. Differ from traditional method, which provides a certain result of minimal gene set, MCCAP believe that minimal gene set is not unique, and it will be difference with different research fields. MCCAP provides a reference species selector interface to users, so that you can get a specific minimal gene set by your purposeful selection.
Most important information of minimal gene set to users is functions of genes. So in the results interface, MCCAP will give the function descriptions of gene firstly. MCCAP have also divided minimal gene set to four categories by their functions reference the standard of COG[2]. In fact, there are 25 function categories of COG. But, it is too complicated for user’s browsing experience. So MCCAP reorganizes them into four categories. These four categories are Transport and metabolism, Transcription and translation, General function prediction only and Others.
In addition to base information, MCCAP will also provide users with information related to KO(KEGG Orthology), EC number of enzymes, COG(Clusters of Orthologous Group) and so on. It is convenient for researchers to do further study.
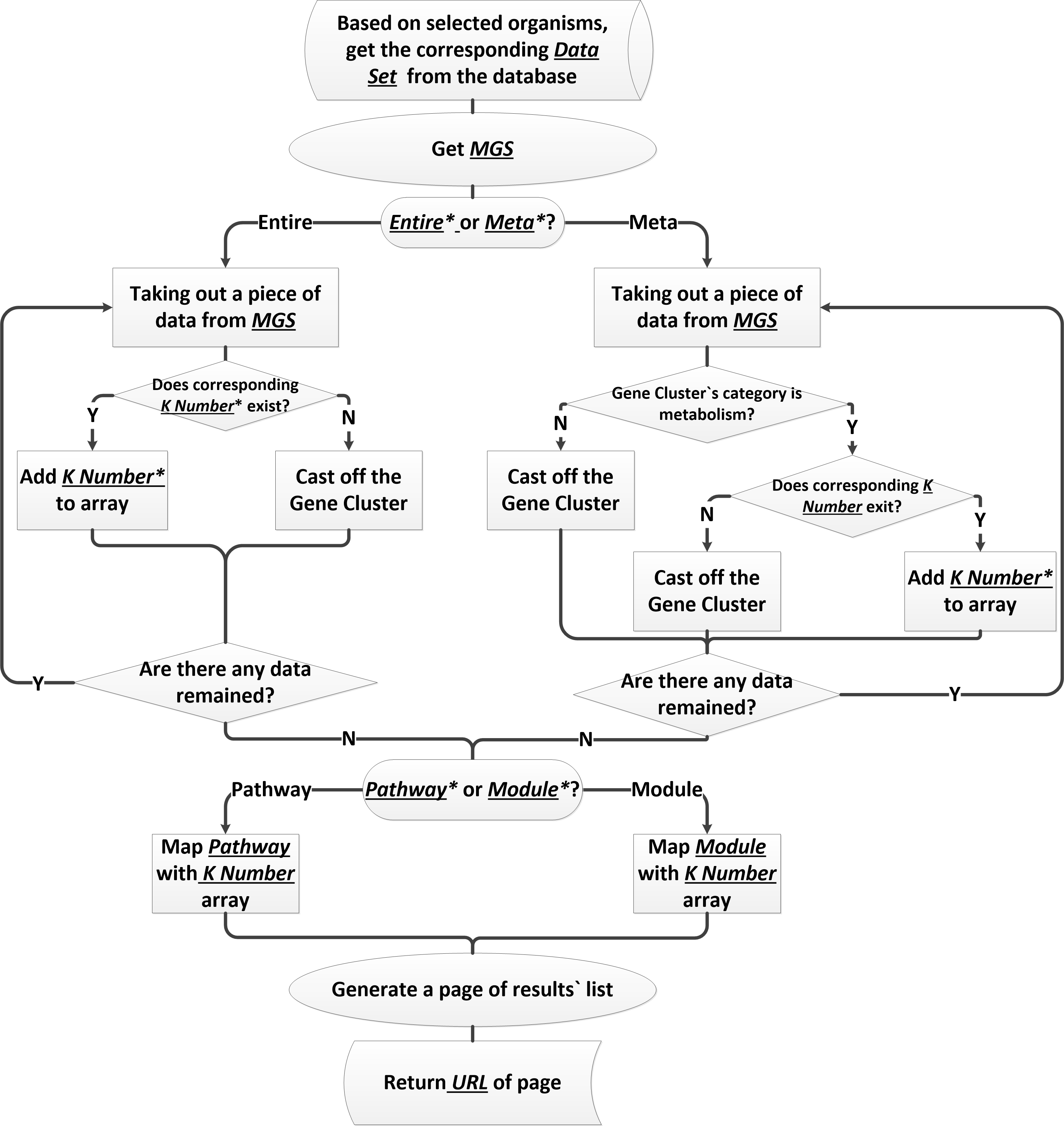
3. Generating gene network diagram
In addition to determining the minimal gene set, there is still a crucial consideration is to know gene metabolism and regulation in building a minimal artificial cell. In order to solve this problem, we combine KEGG Pathway and KEGG Module with the minimal gene set to generate gene network diagram. KEGG Pathway is a collection of manually drawn pathway maps representing our knowledge on the molecular interaction and reaction networks. KEGG Module is a collection of manually defined functional units[3].
Because metabolism is the foundation by which organisms sustain their lives, we divided both pathway and module into two kinds. One’s prefix is Meta, which means gene network diagram generated by only those genes related to metabolism. The other one’s prefix is Entire, which means gene network diagram generated by the whole minimal gene set.
For the functions of fetching information from KEGG, we reused the project of two previous iGEM teams. USTC_Software (https://2014.igem.org/Team:USTC-Software) and Illinois-Tools (https://2009.igem.org/Team:Illinois-Tools).
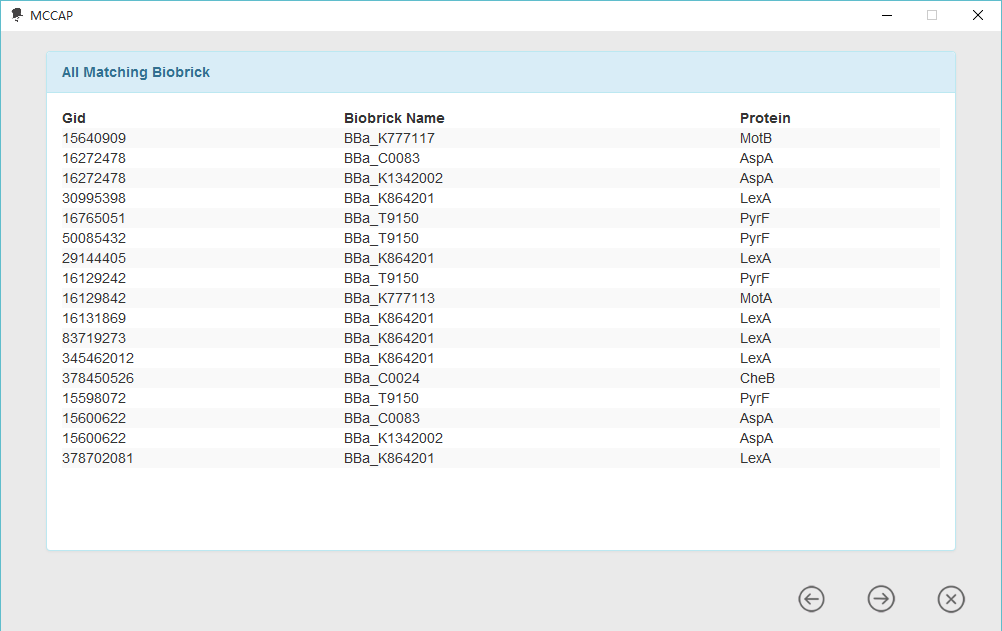
4. Processing gene to standard parts
For researchers aiming to bring their design into reality, MCCAP provi3des information related to standard parts and biobrick assembly standard. So that users can decide which certain gene to use and how to process this gene into a standard part. Currently, biobrick assembly standard supported by MCCAP contains RFC[10], RFC[12], RFC[21], RFC[23] and RFC[25].
Besides, considering the data, there may be some genes which have been processed into standard parts. In order to avoid repeating the wheel, then we tried to find out them from protein coding sequences in registry of standard biological parts. If a gene from minimal gene set has already been processed into a biobrick, MCCAP will provide relevant information and we call it biobrick content. For this kind of gene is really seldom, we also list all of them in a table by considering the user’s convenience.
Reference:
[1] Ye YN, Hua ZG, Huang J, Rao N, Guo FB. CEG: a database of essential gene clusters. BMC Genomics. 2013, 14:769. (From instructor’s group)
[2] Tatusov RL, Galperin MY, Natale DA, Koonin EV. The COG database: a tool for genome-scale analysis of protein functions and evolution. Nucleic Acids Res. 2000, 28(1):33-6.
[3] Kanehisa M, Goto S, Sato Y, Kawashima M, Furumichi M, Tanabe M. Data, information, knowledge and principle: back to metabolism in KEGG. Nucleic Acids Res. 2014, 42(Database issue):199-205.