Difference between revisions of "Team:KU Leuven/Modeling/Hybrid"
| Line 1,693: | Line 1,693: | ||
<h2>Agent-Based Module</h2> | <h2>Agent-Based Module</h2> | ||
<p> | <p> | ||
| − | + | In this paragraph, we will discuss the implementation of | |
| + | the agent-based module. First, the problem of computing | ||
| + | pairwise interactions is discussed and a nearest-neighbor | ||
| + | algorithm is introduced to reduce the computation time. | ||
| + | Then the choice of a timestep is considered especially | ||
| + | with regards to the cell-cell interaction scheme. Finally, | ||
| + | the boundary conditions for agents are defined and explained. | ||
</p> | </p> | ||
</div><!-- part --> | </div><!-- part --> | ||
| Line 1,706: | Line 1,712: | ||
<p> | <p> | ||
The cell-cell interactions have already been fully described in the paragraphs above. However, solving the equation of motion of an agent in its current form requires the computation of the force due to every other agent. If we take N to be the number of agents, that means $N*(N-1)$ amount of force computations are needed in total and therefore the computation time grows as $O(N^2)$. To put this in perspective, if we simulate a thousand agents, the amount of interactions adds up to around one million. This puts a heavy computational load on the model which can be reduced greatly by using a smarter algorithm. The crucial observation here is that the force goes to zero when the distance between two cells is larger than $2\cdot r_{cutoff}$. An agent therefore only interacts with its nearest neighbors, meaning that the naive implementation wastes a lot of time computing interactions which have no effect anyways. Moreover, as the simulation progresses, an agent’s neighbors do not vary greatly from one timestep to another. A more efficient approach then consists of periodically searching for the nearest neighbors within a fixed radius, storing them in a list for every agent and updating their coordinates for all intermediate timesteps. | The cell-cell interactions have already been fully described in the paragraphs above. However, solving the equation of motion of an agent in its current form requires the computation of the force due to every other agent. If we take N to be the number of agents, that means $N*(N-1)$ amount of force computations are needed in total and therefore the computation time grows as $O(N^2)$. To put this in perspective, if we simulate a thousand agents, the amount of interactions adds up to around one million. This puts a heavy computational load on the model which can be reduced greatly by using a smarter algorithm. The crucial observation here is that the force goes to zero when the distance between two cells is larger than $2\cdot r_{cutoff}$. An agent therefore only interacts with its nearest neighbors, meaning that the naive implementation wastes a lot of time computing interactions which have no effect anyways. Moreover, as the simulation progresses, an agent’s neighbors do not vary greatly from one timestep to another. A more efficient approach then consists of periodically searching for the nearest neighbors within a fixed radius, storing them in a list for every agent and updating their coordinates for all intermediate timesteps. | ||
| − | + | <br/> | |
| + | <br/> | ||
Since the agents are programmed to repel each other when they approach each other too closely, they will evolve to a rather uniform distribution. The most appropriate fixed-radius nearest neighbor search algorithm in that case is the cell technique. In this algorithm, the agents are structured by placing a rectangular grid of cells over the domain and assigning every agent to a cell (fig9). Determining which cell an agent belongs to is easily done by rounding down the x and y-coordinates to the nearest multiple of the grid spacing. If the grid spacing is chosen so that interactions do not reach further than adjacent cells, every agent only needs to look for neighbors in 9 cells (its own cells plus 8 adjacent cells) instead of the entire domain. | Since the agents are programmed to repel each other when they approach each other too closely, they will evolve to a rather uniform distribution. The most appropriate fixed-radius nearest neighbor search algorithm in that case is the cell technique. In this algorithm, the agents are structured by placing a rectangular grid of cells over the domain and assigning every agent to a cell (fig9). Determining which cell an agent belongs to is easily done by rounding down the x and y-coordinates to the nearest multiple of the grid spacing. If the grid spacing is chosen so that interactions do not reach further than adjacent cells, every agent only needs to look for neighbors in 9 cells (its own cells plus 8 adjacent cells) instead of the entire domain. | ||
| Line 1,960: | Line 1,967: | ||
<div id="toggleten"> | <div id="toggleten"> | ||
<p> | <p> | ||
| − | + | As mentioned earlier the concentrations of AHL and Leucine | |
| − | + | are modeled using partial differential equations. | |
| − | + | In the colony level model these equations are solved | |
| − | + | explicitly. Explicit schemes do not require a lot of | |
| − | + | work per time step, but unfortunately are not | |
| − | + | unconditionally stable. In two dimensions the grid ratios | |
| − | + | $dt/dx^2$ and $dt/dy^2$ can not exceed $dt/dx^2 + dt/dy^2 | |
| − | + | \leq \frac{1}{2}$ for the solver to be stable. | |
| − | + | When computing the solution of the hybrid model this | |
| − | + | requrement forces us to spend a lot of CPU time solving | |
| − | + | partial differential equations that could be better spent | |
| − | + | simulation the agents. Therefore an implicit ADI | |
| − | + | Alternating direction implicit scheme has been implemented. | |
| − | + | ADI-schemes are unconditionally stable, which | |
| − | + | allows it to take large time steps with the PDE solver. | |
| + | We used the following scheme: | ||
| + | $$ (1 - \frac{1}{2} \mu_x \delta_x^2) U^{n+\frac{1}{2}} | ||
| + | + \frac{1}{4}kU^{n+\frac{1}{2}} | ||
| + | = (1 + \frac{1}{2} \mu_y \delta_y^2) U^n | ||
| + | - \frac{1}{4}kU^n + \frac{\alpha}{2} \rho_A $$ | ||
| + | $$ (1 - \frac{1}{2} \mu_y \delta_y^2) U^{n+1} | ||
| + | + \frac{1}{4}kU^{n+1} = | ||
| + | (1 + \frac{1}{2} \mu_x \delta_x^2)U^{n+\frac{1}{2}} | ||
| + | - \frac{1}{4}kU^{n+\frac{1}{2}} + \frac{\alpha}{2} \rho_A $$ | ||
| + | In the equations above $\mu$ denotes grid ratios and $\delta^2$ | ||
| + | central differences. The production and | ||
| + | degradation terms have been incorporated at every time | ||
| + | level with a factor of $\frac{1}{4}$. | ||
| + | The image below shows the computational molecule of the ADI | ||
| + | scheme we chose to implement: | ||
<br/> | <br/> | ||
</p> | </p> | ||
Revision as of 10:14, 20 November 2015

The Hybrid Model
Introduction
The hybrid model represents an intermediate level of detail in between the colony level model and the internal model. Bacteria are treated as individual agents that behave according to Keller-Segel type stochastic differential equations, while chemical species are modeled using partial differential equations. These different models are implemented and coupled within a single hybrid modeling framework.
Partial Differential Equations
Spatial reaction-diffusion models that rely on Partial Differential Equations (PDEs) are based on the assumption that the collective behavior of individual entities, such as molecules or bacteria, can be abstracted to the behavior of a continuous field that represents the density of those entities. The brownian motion of molecules, for instance, is the result of inherently stochastic processes that take place at the individual molecule level, but is modeled at the density level by Fick’s laws of diffusion. These PDE-based models provide a robust method to predict the evolution of large-scale systems, but are only valid when the spatiotemporal scale is sufficiently large to neglect small-scale stochastic fluctuations and physical granularity. Moreover, such a continuous field approximation can only be made if the behavior of the individual entities is well described.
Agent-Based Models
Agent-based models on the other hand explicitly treat the entities as individual “agents” that behave according to a set of “agent rules”. An agent is an object that acts independently from other agents and is influenced only by its local environment. The goal in agent-based models is to study the emergent systems-level properties of a collection of individual agents that follow relatively simple rules. In smoothed particle hydrodynamics for example, fluids are simulated by calculating the trajectory of each individual fluid particle at every timestep. Fluid properties such as the momentum at a certain point can then be sampled by taking a weighted sum of the momenta of the surrounding fluid particles. A large advantage of agent-based models is that the agent rules are arbitrarily complex and thus they allow us to model systems that do not correspond to any existing or easily derivable PDE model. However, because every agent is stored in memory and needs to be processed individually, simulating agent-based models can be computationally intensive.
Hybrid Modeling Framework
In our system, there are both bacteria and chemical species that spread out
and interact on a petri dish to form patterns. On the one hand, the bacteria are
rather complex entities that move along chemical gradients and interact with one
another. Therefore they are ideally modeled using an agent-based model. On the
other hand, the diffusion and dynamics of the chemicals leucine and AHL are
easily described by well-established PDEs. To make use of the advantages of each
modeling approach, we decided to combine these two different types of modeling
in a hybrid modeling framework. In this framework we modeled the bacteria as
agents, while the chemical species were modeled using PDEs. There were two
challenges to our hybrid approach, namely coupling the models and matching them.
Coupling refers to the transfer of information between the models and matching
refers to dealing with different spatial and temporal scales to achieve
accurate, yet computationally tractable simulations.
In the following paragraphs we first introduce our hybrid model and its
coupling. Once the basic framework is established, the agent-based module and
PDE module are discussed in more depth and the issue of matching is highlighted.
We also expand on important aspects of the model and its implementation such as
boundary conditions and choice of timesteps. Then the results for the 1-D model
and 2-D model simulations are shown and summarized. Finally, the incorporation
of the internal model into the hybrid model is discussed and a proof of concept
is demonstrated.
Model Description
System
The main protagonists in our pattern-forming system are cell types A and B, AHL and leucine. Cells A produce AHL as well as leucine. They are unaffected by leucine, while cells B are repelled by leucine. AHL modulates the motility of both cell types A and B, but in opposite ways. High concentrations of AHL will render cell type A unable to swim but will activate cell type B’s motility. Conversely, low concentrations of AHL causes swimming of cell type A and incessant tumbling (thus immobility) of cell type B. Lastly, cells A express the adhesin membrane protein, which causes them to stick to each other. Simply said, our system should produce spots of immobile, sticky groups of A type cells, surrounded by rings of B type cells. Any cell that finds itself outside of the region that it should be in, is able to swim to their correct place and becomes immobile there. More details can be found in the research section.
Partial Differential Equations
As discussed in the previous paragraph, our hybrid model incorporates chemical species using PDEs. In our system these are AHL and leucine. The diffusion of AHL and leucine can be described by the heat equation (1).
$$\frac{\partial C(\vec{r},t)}{\partial t}=D \cdot \nabla^2 C(\vec{r},t) \;\;\; \text{(1)}$$
By using (1) we assume that the diffusion speed is isotropic, i.e. the same in all spatial directions. This also explains why it is called the heat equation, since heat diffuses equally fast in all directions. A detailed explanation of the heat equation can be found in box 1. The second factor that needs be taken into account is the production of AHL and leucine by type A bacteria. In principle, AHL and leucine production is dependent on the dynamically-evolving internal states of all cells of type A. However, for our hybrid model we ignored the inner life of all bacteria and instead assumed that AHL and leucine production is directly proportional to the density of A type cells (2).
$$ \frac{\partial C(\vec{r},t)}{\partial t}=\alpha \cdot \rho_A(\vec{r},t) \;\;\; \text{(2)}$$
In the last paragraph we will reconsider this assumption and assign each cell an internal model. Finally, AHL and leucine are organic molecules and therefore they will degrade over time. We assume first-order kinetics meaning that the rate at which AHL and similarly leucine disappear is proportional to their respective concentrations (3a and 3b) assuming neutral pH [6].
$$ \frac{\partial C_{AHL}(\vec{r},t)}{\partial t}=-k_{AHL}\cdot C_{AHL}(\vec{r},t) \;\;\; \text{(3a)} $$ $$ \frac{\partial C_{leucine}(\vec{r},t)}{\partial t}=-k_{leucine}\cdot C_{leucine}(\vec{r},t) \;\;\; \text{(3b)} $$
Putting it all together, we obtain (4), both for AHL and leucine.
$$ \frac{\partial C(\vec{r},t)}{\partial t}=D \cdot \nabla^2 C(\vec{r},t)+\alpha \cdot \rho_A(\vec{r},t)-k\cdot C(\vec{r},t) \;\;\; \text{(4)} $$
Note that these equations have exactly the same form as the equations for AHL and leucine in the colony level model. The crucial difference however lies in the calculation of the density of cells of type A. In contrast to the colony level model, in this model the cell density is not calculated explicitly with a PDE and is therefore not trivially known. Therefore a method to extract a density field from a spatial distribution of agents is necessary. This is addressed in the subparagraph below on coupling.
Box 1: Heat Equation
Heat Equation
The left-hand side of the heat equation (1) represents the rate of accumulation of a chemical, while the right-hand side is proportional to the Laplacian of its concentration field, which is a second-order differential operator. This equation can be easily understood by considering a one-dimensional concentration profile, as shown in Figure 1: if the concentration can be approximated as a convex parabolic function, the second derivative is positive and therefore the rate of accumulation is positive (i.e. more accumulation). If on the other hand the concentration resembles a concave parabolic function, the second derivative is negative and the rate of accumulation as well (i.e. depletion). A special case occurs when the concentration profile takes on a linear form. Everything that moves into the point goes out at the other side and as a result there is no net accumulation over time.
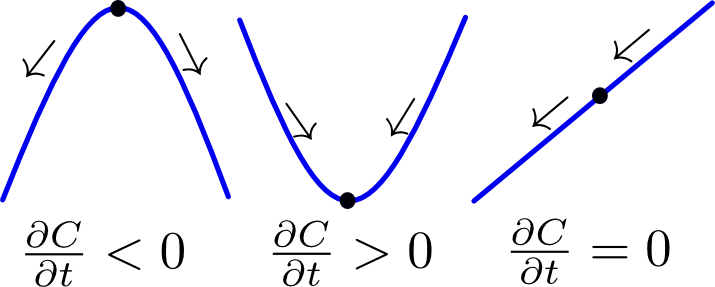
Figure 1 Illustration of the heat equation. Click to enlarge.
In the videoplayer below we demonstrate how the heat equation smoothes out an initially heterogeneous concentration profile. When only diffusion is acting on the system, it will always evolve to a uniformly flat concentration profile, regardless of the initial conditions.
Agents
To model bacteria movement on the other hand, we used an agent-based model that explicitly stored individual bacteria as agents. Spatial coordinates are associated with each agent, specifying their location. After solving the equation of motion for all agents based on their environment, these coordinates are updated at every timestep. In principle, Newton’s second law of motion has to be solved for all bacteria. However, since bacteria live in a low Reynolds (high friction) environment, the inertia of the bacteria can be neglected. This is because an applied force will immediately be balanced out by an opposing frictional force, with no noticeable acceleration or deceleration phase taking place. This eliminates the inertial term and simplifies Newton’s second law to (5).
$$ \frac{d^2 \vec{r}(t)}{dt^2}=\sum_{i} \vec{F}_{applied,i}-\gamma \cdot \frac{d \vec{r}(t)}{dt}=0 $$ $$\Rightarrow \frac{d \vec{r}(t)}{dt}=\frac{1}{\gamma} \cdot \sum_{i} \vec{F}_{applied,i} \;\;\; \text{(5)} $$
Basically, the velocity can be calculated as the sum of all applied forces times divided by a frictional coefficient. For more info about the Reynolds number and “life at low Reynolds number”, we refer to box 2. In the following paragraphs we will investigate the different forces acting on the bacteria and ultimately superimpose them to obtain the final equation of motion.
Box 2: Life at Low Reynolds Number
Life at Low Reynolds Number
The Reynolds number in fluid mechanics is a dimensionless number that characterizes different flow regimes. It is most commonly used to determine whether laminar or turbulent flow will take place in a hydrodynamic system (Figure 2).
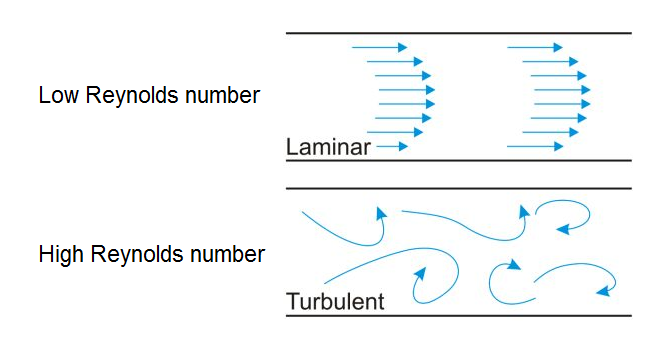
Figure 2
Flow regimes for different Reynolds numbers. Click to enlarge.
In general however, it quantifies the ratio of inertial forces to viscous forces and is defined as (B2.1).
$$ Re=\frac{\text{inertial forces}}{\text{viscous forces}} =\frac{\rho v^2 L^2}{\eta v L} =\frac{\rho v L}{\eta} \;\;\; \text{(B2.1)} $$
For example, if the Reynolds number is high, the inertia of fluids in motion dominate and
turbulent flow will occur. When it is low however, the viscous forces dampen
the kinetic energy of fluid particles and stabilize the flow profile, ultimately
achieving a regular, laminar flow.
The reason we mention the Reynolds number however is not to study the flow of fluids, but
to characterize the behavior of swimming objects inside of a stationary fluid.
When applied to objects in a fluid, the Reynolds number tells us whether their inertia
can be neglected or not. For bacteria, the characteristic length $L$ is on the order
of micrometers, which is quite small. Therefore the Reynolds number is always
very small and hence viscous forces dominate the motion of bacteria. This is what allows
us to eliminate the inertial term in Newton's second law and greatly simplify the
equation of motion.
To justify this simplification we will go through a numerical example.
Take a bacterium of size $L = 2 a = 1 \cdot \mu m$, swimming through water with a speed of
$v=20 \cdot \mu m/s$. Water has a density of $\rho = 1 \; 000 \cdot kg/m^3$
and a viscosity of $\eta = 0.001 \cdot Pa/s$.

Figure 3
Sketch of swimming bacterium. Click to enlarge.
Putting these values in (B2.1) yields a Reynolds number of $Re = 2 \cdot 10^{-5} << 1$. Clearly we are in an extremely low Reynolds number regime. To show what this really means, suppose the bacterium stops propelling itself. How long will it continue to move relying only on its inertia? Assuming Stokes' law, we obtain (B2.2) as the equation of motion.
$$ F=m\cdot \frac{d^2x}{dt^2} \;\;\; \text{(B2.2a)} $$ $$ -6 \pi \eta a v=m\cdot \frac{dv}{dt} \;\;\; \text{(B2.2b)} $$
Solving this differential equation yields (B2.3).
$$ v=v_0 \cdot \text{exp} \Bigg[ -\frac{6 \pi \eta a}{m} \cdot (t-t_0) \Bigg] \;\;\; \text{(B2.3)} $$
The characteristic time constant is $\tau = 6\pi\eta a/m \approx 0.1 \cdot \mu s$, from which we calculate that the total distance traversed is $\Delta x < 2 \cdot pm$. This coasting distance is 6 orders of magnitude smaller than its size. Moreover, the time spent coasting is extremely short. Thus, once the bacterium stops propelling itself, it is safe to assume that whatever kinetic energy it had is immediately absorbed by hydrodynamic friction, instantly halting the bacterium. Therefore, we can neglect the inertial term in Newton's second law (5).
Cell-Cell Interactions
In addition to chemotaxis and diffusion, cell-cell interactions play an important role in pattern formation and also need to be modeled. Bacteria have finite size and therefore multiple bacteria cannot occupy the same space. Moreover, an important mechanism in our system is the aggregation of cells A due to the sticky adhesin protein membrane. To take these mechanisms into account we modeled two types of cell-cell interactions: the purely repulsive interaction of cell B with another cell B and with cell A, and the attractive-repulsive interaction of cell A with another cell A. The interaction between two cells is usually expressed by a potential energy curve defined over the distance between the centers of mass of the two cells (Figure 2).
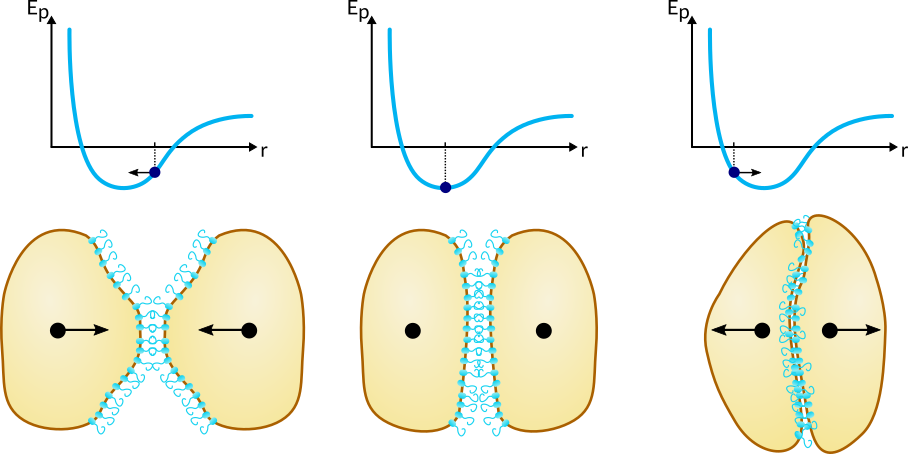
Figure 2Cell-cell interaction potential. Click to enlarge.
Note that the potential energy remains constant after a certain distance, which means that the cells stop interacting. Also, as two cells move closer together, they hit a wall where the potential energy curve abruptly goes to infinity. The reason for this is that two cells cannot occupy the same space and therefore smaller intercellular distances are not allowed. Implementing this theoretical potential is however not possible because the displacement of bacteria is a stochastic process and the bacteria could randomly jump beyond the potential wall, where the force is ill defined. Therefore, we’ve decided to define a piecewise quadratic potential (9), which results in a piecewise linear force that resembles Hooke’s law, but with three different “spring constants” acting in different intervals of intercellular distances (10), as illustrated in Figure 3. The force is defined with respect to the unit vector pointing towards the other cell, meaning that a positive force corresponds to an attractive force and vice-versa.
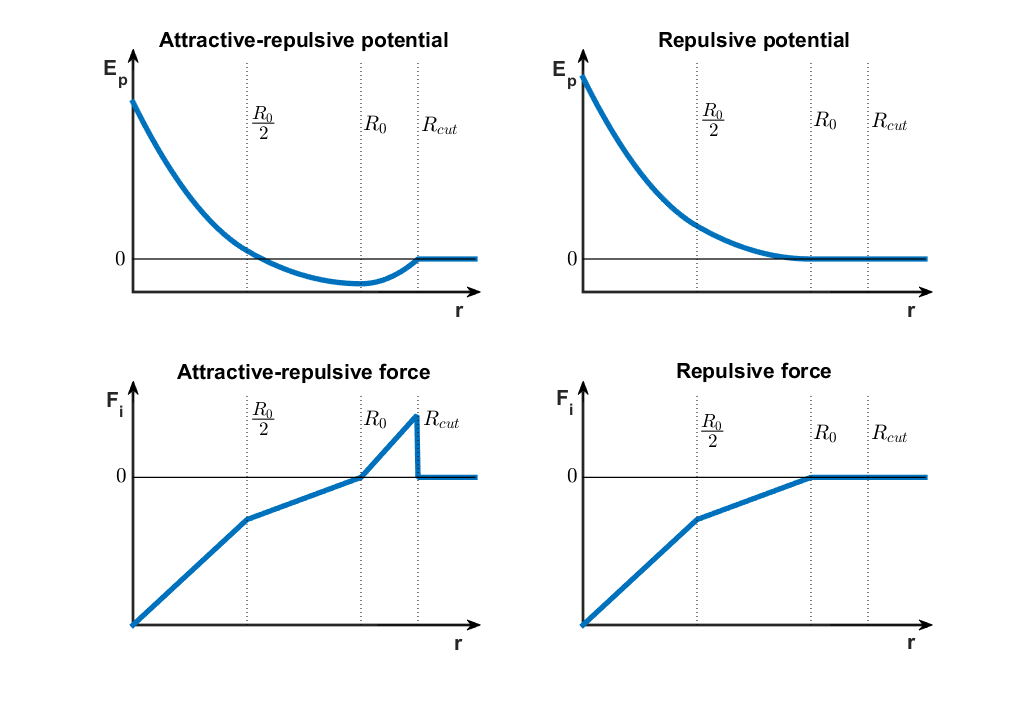
Figure 3Cell-cell interaction potential and force curves. Click to enlarge.
$$ E_{p,attr-rep}(r_{ij})=\left\{\begin{matrix} 0 & R_{cutoff}\leq r_{ij}\\ \frac{1}{2}\cdot k_3 \cdot(r_{ij}-R_0)^2+C_1 & R_0 \leq r_{ij} < R_{cutoff} \\ \frac{1}{2}\cdot k_2 \cdot(r_{ij}-R_0)^2+C_1 & \frac{R_0}{2} \leq r_{ij} < R_0\\ \frac{1}{2}\cdot k_1 \cdot(r_{ij}-\frac{k_1+k_2}{k_1}\cdot \frac{R_0}{2})^2+C_2 & 0 \leq r_{ij} < \frac{R_0}{2} \end{matrix}\right. \;\;\; \text{(9a)}$$ $$ E_{p,rep}(r_{ij})=\left\{\begin{matrix} 0 & R_0\leq r_{ij}\\ \frac{1}{2}\cdot k_2 \cdot(r_{ij}-R_0)^2 & \frac{R_0}{2} \leq r_{ij} < R_0\\ \frac{1}{2}\cdot k_1 \cdot(r_{ij}-\frac{k_1+k_2}{k_1}\cdot \frac{R_0}{2})^2 & 0 \leq r_{ij} < \frac{R_0}{2} \end{matrix}\right. \;\;\; \text{(9b)}$$
$$ \vec{F}_{i,attr-rep}(r_{ij})= \frac{\partial E_{p,attr-rep}(r_{ij})}{\partial r_{ij}} \cdot \vec{e}_{ij}= \left\{\begin{matrix} \vec{0} & R_{cutoff}\leq r_{ij}\\ k_3 \cdot(r_{ij}-R_0) \cdot \vec{e}_{ij} & R_0 \leq r_{ij} < R_{cutoff} \\ k_2 \cdot(r_{ij}-R_0) \cdot \vec{e}_{ij} &\frac{R_0}{2} \leq r_{ij} < R_0\\ k_1 \cdot(r_{ij}-\frac{k_1+k_2}{k_1}\cdot \frac{R_0}{2}) \cdot \vec{e}_{ij} & 0 \leq r_{ij} < \frac{R_0}{2} \end{matrix}\right. \;\;\; \text{(10a)} $$ $$ \vec{F}_{i,rep}(r_{ij})= \frac{\partial E_{p,rep}(r_{ij})}{\partial r_{ij}} \cdot \vec{e}_{ij}= \left\{\begin{matrix} \vec{0} & R_0\leq r_{ij}\\ k_2 \cdot(r_{ij}-R_0) \cdot \vec{e}_{ij} & \frac{R_0}{2} \leq r_{ij} < R_0\\ k_1 \cdot(r_{ij}-\frac{k_1+k_2}{k_1}\cdot \frac{R_0}{2}) \cdot \vec{e}_{ij} & 0 \leq r_{ij} < \frac{R_0}{2} \end{matrix}\right. \;\;\; \text{(10b)} $$
Between A type cells, there is a region of attraction $(R_0 \leq r_{ij} < R_{cutoff})$, where the force points towards the other cell, hence moving them closer together. In the repulsive domain $(r_{ij} < R_0)$, two regions were defined, emulating lower repulsive forces $(\frac{R_0}{2} \leq r_{ij} < R_0)$ and higher repulsive forces due to a higher spring constant when the cells are even closer $(r_{ij} < \frac{R_0}{2})$. For the purely repulsive interaction scheme there is no attraction and therefore the spring constant for $R_0 \leq r_{ij}$ is zero. More details about the implementation of the cell-cell interaction scheme, more specifically regarding the nearest-neighbor search algorithm, can be found in the paragraph on the agent-based module below.
Coupling
At this point, both the PDE module and agent-based module have been established,
but the issue remains that the individual modules take inputs and return outputs which are not
directly compatible. In the framework of PDEs, entities are described by
density/concentration fields.
In the agent-based module however, entities are represented by discrete
objects with exact spatial locations. The key challenge posed by the hybrid model
is to integrate these different approaches by bidirectionally converting and
exchanging information between the modules. Coupling the modules is the essential component
that makes the hybrid model hybrid. It allows us to leverage the advantages
of both modeling approaches, while circumventing their drawbacks. But although
hybrid modeling opens up many new avenues for novel modeling methods,
it comes with its own diverse set of issues and peculiarities that need to be
addressed before it can be successfully applied.
In the following paragraphs the basic scheme for coupling
the PDE and agent-based modules in our model is introduced, after which the theoretical
treatment of our hybrid model is complete. The difficulties that arise from linking the
modules together are discussed further below in the subsection on matching.
Agent-Based to PDE
As described above, the agents’ effect in the PDE is modeled as a source term that is proportional to the agent density. This approach is essentially the same approach taken in the colony level model for the bacterial production of AHL and leucine. However, in the colony level model the bacteria density is explicitly calculated at the grid points, while the agent-based model essentially considers a set of points scattered in space. A simple first-order approach would be to determine the closest grid point to any agent and simply increment a counter belonging to that grid point. This results in a histogram, which can be used directly to represent the agent density. However, the resulting density is a blocky, nonsmooth function which poorly represents the underlying agent distribution. The effect of a single agent is artificially confined to a single grid point, while in reality an agent’s influence could reach much further than a single grid point. The shape of a histogram is also very dependent on the bin size, which in this case corresponds to the grid spacing so it cannot be independently tuned. To decouple grid spacing and agent density and achieve a smoother density function, we made use of a more sophisticated technique called kernel density estimation (KDE).
KDE is used in statistics to estimate the probability density of a set discrete data derived from a random process. The basic idea consists of defining a kernel function that represents the density of a single data point, then centering kernel functions on every data point and summing them all up to achieve a smooth overall density function, as demonstrated in the Figure 4.
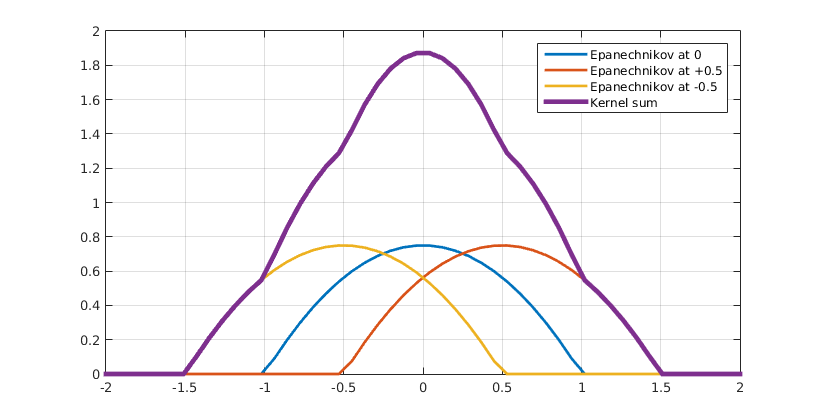
Figure 4 Kernel density estimation. Click to enlarge.
This kernel function can be anything as long is it continuous, symmetric and integrates to 1, since it represents one data point or one agent in our case. Some of the most common kernel functions include Gaussian kernels, triangular kernels and Epanechnikov kernels (14), which are shown in Figure 5.
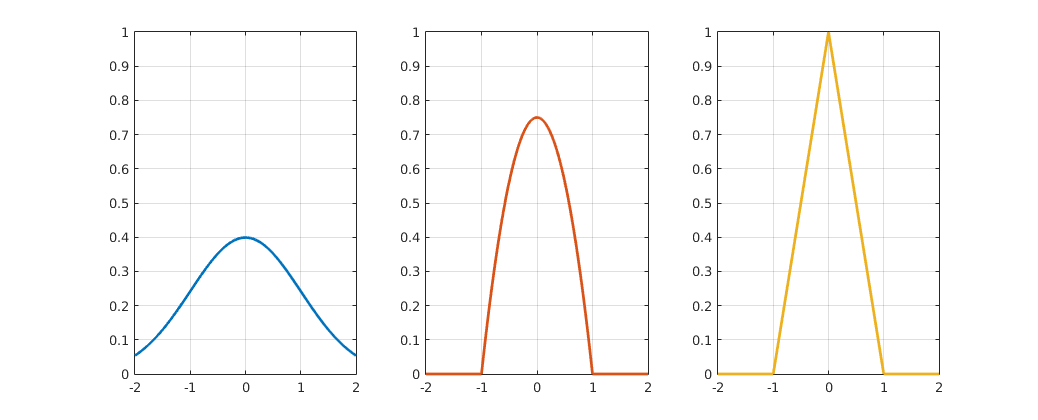
Figure 5
Gaussian, triangular and Epanechnikov kernel functions.
Click to enlarge.
$$ K_{Gaus}(x)=\frac{1}{\sqrt{2 \cdot \pi}} \cdot e^{-\frac{1}{2}x^2} \;\;\; \text{(14a)} $$ $$ K_{tri}(x)=\left\{\begin{matrix} 0 & 1 < |x| \\ 1-|x| & |x| \leq 1 \end{matrix}\right. \;\;\; \text{(14b)} $$ $$ K_{Epa}(x)=\left\{\begin{matrix} 0 & 1 < |x| \\ \frac{3}{4} \cdot (1-x^2) & |x| \leq 1 \end{matrix}\right. \;\;\; \text{(14c)} $$
In practice, scaled versions of standard kernel functions are used, which are of the form (15).
$$ K_h(x)=\frac{1}{h} \cdot K \bigg( \frac{x}{h} \bigg) \;\;\; \text{(15)} $$
Importantly, the scaled functions inherit the kernel function properties, but are either broader or narrower. The degree to which the shape of a kernel function is stretched or squeezed depends on the scaling factor h, which is why it is called the bandwidth, see Figure 6.
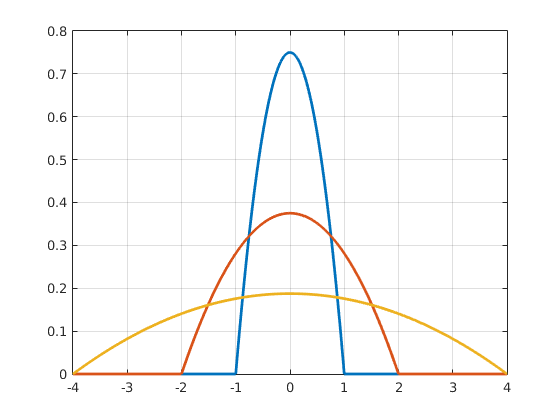
Figure 6Epanechnikov kernels using different bandwidths. Click to enlarge.
This parameter gives us the freedom to define how far the influence of an agent reaches and how smooth the resulting density function looks like. An example is given in Figure 7, where 100 agents were sampled from a normal distribution. The red dotted line indicates the true underlying distribution, while the blue line is the kernel density estimation calculated using different bandwidths. The left graph shows a undersmoothed (small bandwidth) KDE, which oscillates wildly. The right graph on the other hand is oversmoothed (large bandwidth), leading to a misleadingly wide KDE.
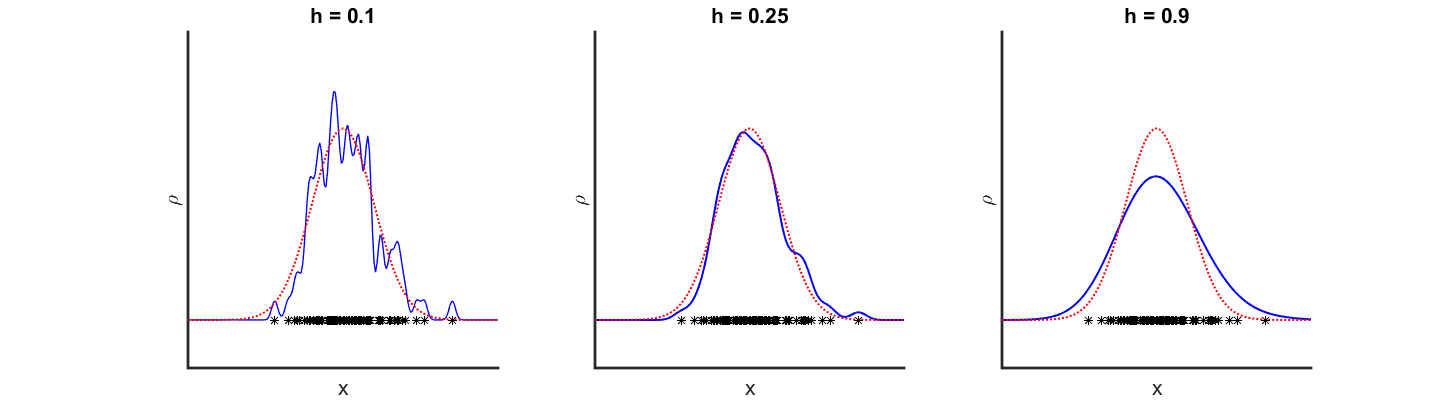
Figure 7Kernel density estimation using different bandwidths. Click to enlarge.
In summary, using kernel density estimation we can express the agent density in the form of (16), providing the appropriate input for the PDE model.
$$ \rho(x)=\beta \cdot \sum^N_{i} K_h(x-x_i) \;\;\; \text{(16)} $$
The extension to higher dimensions is called multivariate kernel density estimation and is rather non-trivial since the bandwidth is then defined as a matrix instead of a scalar, which allows for many more variations on the same basis kernel function. A detailed analysis of multivariate kernel density estimation will not be given here. It suffices to say that for our 2-D hybrid model we used the simplest possible bandwidth matrix, which is the identity matrix times a constant.
Box 3: Bilinear Interpolation
Bilinear Interpolation
Interpolation is used to obtain a continuous function when a finite amount of data points are known. Piecewise linear interpolation is the most simple scheme to interpolate 1-dimensional data.
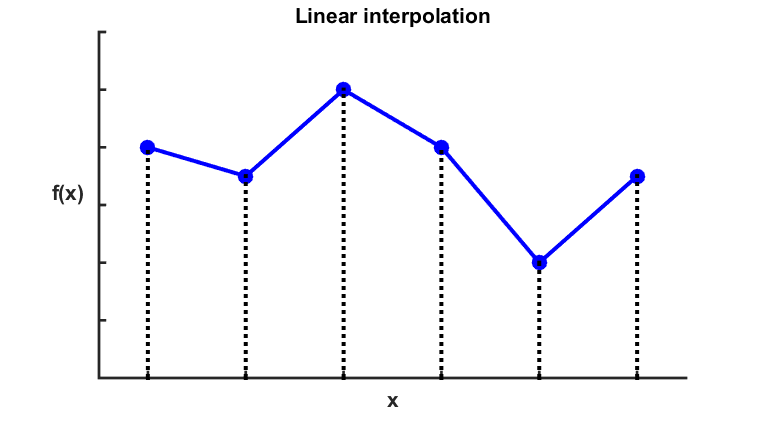
Figure 8
Illustration of linear interpolation. Click to enlarge.
The technique involves defining linear functions connecting consecutive data points to fill in the gaps, using (B3.1).
$$ \hat{f}(x)=f(x_i)+\frac{f(x_{i+1})-f(x_i)}{x_{i+1}-x_i} \cdot (x-x_i) \; \text{for} \; x_i < x < x_{i+1} \;\;\; \text{(B3.1)} $$
Bilinear interpolation is the generalization of this interpolation technique to two dimensions, illustrated using Figure 9.
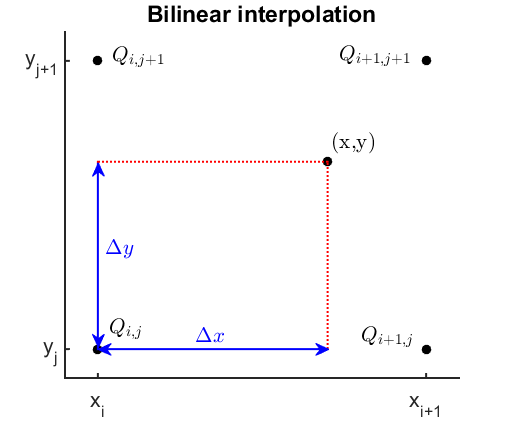
Figure 9
Illustration of bilinear interpolation. Click to enlarge.
Let’s assume we want to interpolate a two-dimensional function within a rectangular domain where the function values are only known on the four adjacent grid points $Q$. First we linearly interpolate in the x-direction on the lines connecting $Q_{i,j}$ and $Q_{i+1,j}$, $Q_{i,j+1}$ and $Q_{i+1,j+1}$, which yields (B3.2).
$$ \hat{f}(x,y_j)=\frac{x_{i+1}-x}{x_{i+1}-x_i} \cdot f(Q_{i,j}) + \frac{x-x_i}{x_{i+1}-x_i} \cdot f(Q_{i+1,j}) \;\;\; \text{(B3.2a)} $$ $$ \hat{f}(x,y_{j+1})=\frac{x_{i+1}-x}{x_{i+1}-x_i} \cdot f(Q_{i,j+1}) + \frac{x-x_i}{x_{i+1}-x_i} \cdot f(Q_{i+1,j+1}) \;\;\; \text{(B3.2b)} $$
We then obtain interpolated values for all positions on the bottom and top edge. The key idea then is to take these values and interpolate in the y-direction for any given x-position, yielding (B3.3).
$$ \hat{f}(x,y)=\frac{y_{j+1}-y}{y_{j+1}-y_j} \cdot \hat{f}(x,y_j) + \frac{y-y_j}{y_{j+1}-y_j} \cdot \hat{f}(x,y_{j+1}) \\ =\frac{y_{j+1}-y}{y_{j+1}-y_j} \cdot \Bigg[ \frac{x_{i+1}-x}{x_{i+1}-x_i} \cdot f(Q_{i,j}) + \frac{x-x_i}{x_{i+1}-x_i} \cdot f(Q_{i+1,j}) \Bigg] \\ +\frac{y-y_j}{y_{j+1}-y_j} \cdot \Bigg[ \frac{x_{i+1}-x}{x_{i+1}-x_i} \cdot f(Q_{i,j+1}) + \frac{x-x_i}{x_{i+1}-x_i} \cdot f(Q_{i+1,j+1}) \Bigg] \;\;\; \text{(B3.3)} $$
This then gives interpolated values for any point within the domain. Note that the resulting function is not linear, but quadratic since it contains the term $x \cdot y$.
Synthesis
The diffusion, production and degradation of AHL and leucine are described by the PDEs (4). At the same time, the random movement, chemotaxis and intercellular interactions of cell types A and B are captured by the stochastic equation of motion (11). Translating the spatial distribution of cells type A into a density field to feed into the PDE module can be accomplished by using kernel density estimation (16). Finally, the agents can request concentrations and gradients at arbitrary positions from the PDE module using bilinear interpolation (B3.3). Taken together, these equations describe the individual modules, as well as the two-way information transfer in between them, and thus they fully define our hybrid model. A graphical summary is shown in Figure 10.
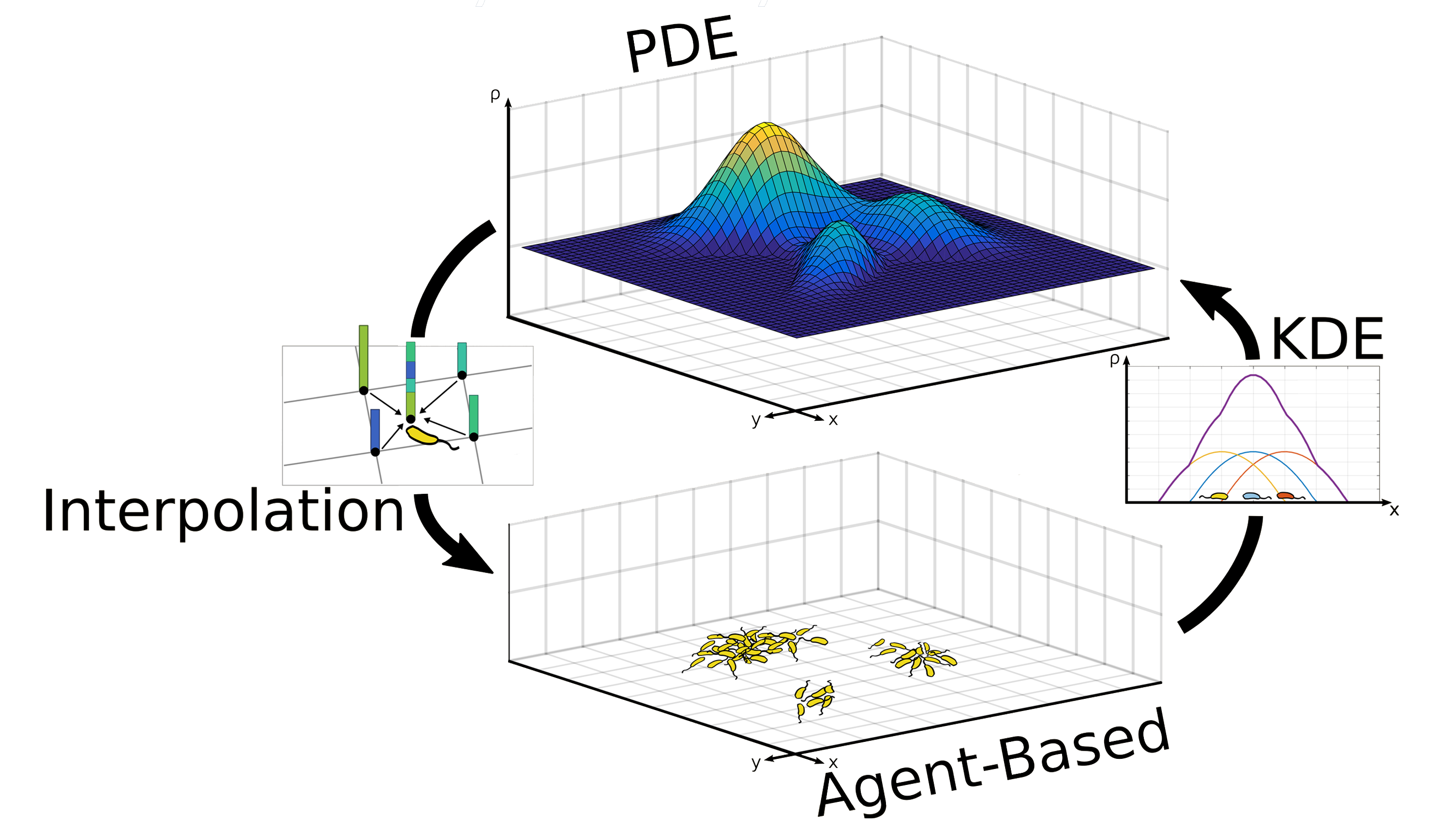
Figure 10
Graphical summary of hybrid model. Click to enlarge.
Implementation
Agent-Based Module
In this paragraph, we will discuss the implementation of the agent-based module. First, the problem of computing pairwise interactions is discussed and a nearest-neighbor algorithm is introduced to reduce the computation time. Then the choice of a timestep is considered especially with regards to the cell-cell interaction scheme. Finally, the boundary conditions for agents are defined and explained.
Partial Differential Equations Module
Introductory text about the Partial Differential Equations Module
Computational Scheme
As mentioned earlier the concentrations of AHL and Leucine
are modeled using partial differential equations.
In the colony level model these equations are solved
explicitly. Explicit schemes do not require a lot of
work per time step, but unfortunately are not
unconditionally stable. In two dimensions the grid ratios
$dt/dx^2$ and $dt/dy^2$ can not exceed $dt/dx^2 + dt/dy^2
\leq \frac{1}{2}$ for the solver to be stable.
When computing the solution of the hybrid model this
requrement forces us to spend a lot of CPU time solving
partial differential equations that could be better spent
simulation the agents. Therefore an implicit ADI
Alternating direction implicit scheme has been implemented.
ADI-schemes are unconditionally stable, which
allows it to take large time steps with the PDE solver.
We used the following scheme:
$$ (1 - \frac{1}{2} \mu_x \delta_x^2) U^{n+\frac{1}{2}}
+ \frac{1}{4}kU^{n+\frac{1}{2}}
= (1 + \frac{1}{2} \mu_y \delta_y^2) U^n
- \frac{1}{4}kU^n + \frac{\alpha}{2} \rho_A $$
$$ (1 - \frac{1}{2} \mu_y \delta_y^2) U^{n+1}
+ \frac{1}{4}kU^{n+1} =
(1 + \frac{1}{2} \mu_x \delta_x^2)U^{n+\frac{1}{2}}
- \frac{1}{4}kU^{n+\frac{1}{2}} + \frac{\alpha}{2} \rho_A $$
In the equations above $\mu$ denotes grid ratios and $\delta^2$
central differences. The production and
degradation terms have been incorporated at every time
level with a factor of $\frac{1}{4}$.
The image below shows the computational molecule of the ADI
scheme we chose to implement:

Figure 4 ADI-Molecule. Click to enlarge.
Matching
Introductory text about matching
Decoupling of Timesteps
In order to benefit from the implicit PDE-solver described above the agent's time steps are chosen smaller then the time steps of the PDE solver. However type A cells produce molecules continuously as they move trough space. Therefore we record their positions and average over the kernel functions centered at past positions since the last PDE evaluation. That way we avoid blurring the results of the PDE solver too much, when the time step of the agents is reduced. Last but not least we want to point out the relationship between kernel bandwidth and the grid on which the PDE is solved. The larger the kernel bandwidth $h$ is chosen the coarser the PDE grid can be without loosing cells between grid points. If the the diameter of the kernel functions is smaller then the distance between PDE grid points it can happen, that the kernel does not overlap with any PDE grid points. In this case a cells contribution to the molecule concentrations at the next time step could be lost. When the PDE grid is widened to save computing time it is thus necessary to increase the Kernel bandwidth as well. However this increase can lead to a situation where the Kernel function covers significantly more space then the actual diameter of a bacterium. In these cases the Kernel function can be interpreted as a probability function for a cells position. However we avoided too large bandwiths and PDE grids by running our 2-D simulations at the Flemish Supercomputer Center (VSC).
Figure 6 Logo of the Flemish Supercomputer Center. Click to enlarge.
1-D Hybrid Model
The video box above shows one dimensional simulation results for the hybrid model. A constant speed and random step simulation has been computed. We observe that the bacteria form a traveling wave in both cases, which is essential for pattern formation. These results are also similar to what we get from the continuous model, which confirms our results.
2-D Hybrid Model
The videos above show simulation videos computed at the Flemish supercomputing center, for three different initial conditions similar to the ones we used for the colony level model. The first and second condition start from 9 mixed or 5 colonies of both cell types, arranged in a block or star shape. These first two gradually separate in a manner similar to what we would we also saw in the colony level model. The result for random initial data is fundamentally different. As the agent based approach allows for better implementation of adhesion large cell type A bands form. The AHL and Leucine produced by the type A bacteria causes the B type cells to move away leading to a pattern which we could not produce using PDEs alone, this beautifully illustrates the added value of hybrid modeling.
Incorporation of internal model
Up until now, we have largely ignored the inner life of the bacteria. This inner life consists of transcriptional networks and protein kinetics. Instead we assumed that AHL and leucine production is directly proportional to the density of type A cells. This only works in theory, since bacteria will be affected by their surroundings and the way their dynamics react to it. For example bacteria surrounded by a large concentration of AHL, will have more CheZ and will react more on the presence of Leucine. Also bacteria have different histories and will have different levels of transcription factors and different levels of proteins in their plasma. The proteins are not directly degraded and will still be present in the cytoplasm of the bacteria long after the network has been deactivated. From this, it is clear that 2 bacteria, although surrounded by the same AHL and leucine concentrations, can show different behavior and reaction kinetics.
This results in a heterogeneity of the bacterial population that has not yet been accounted for. To make up for this anomaly, we decided to add an internal model to every agent. This way we will get more realistic simulations. Every agent will get their own levels of CheZ, LuxR, LuxI and so on and will have individual reactions on their surroundings. We hope that this way we can get closer to the behavior of real bacteria.
References
| [1] | Benjamin Franz and Radek Erban. Hybrid modelling of individual movement and collective behaviour. Lecture Notes in Mathematics, 2071:129-157, 2013. [ .pdf ] |
| [2] | Zaiyi Guo, Peter M A Sloot, and Joc Cing Tay. A hybrid agent-based approach for modeling microbiological systems. Journal of Theoretical Biology, 255(2):163-175, 2008. [ DOI ] |
| [3] | E F Keller and L A Segel. Traveling bands of chemotactic bacteria: a theoretical analysis. Journal of theoretical biology, 30(2):235-248, 1971. [ DOI ] |
| [4] | E. M. Purcell. Life at low Reynolds number, 1977. [ DOI ] |
| [5] | Angela Stevens. The Derivation of Chemotaxis Equations as Limit Dynamics of Moderately Interacting Stochastic Many-Particle Systems, 2000. [ DOI ] |
| [6] | A. L. Schaefer, B. L. Hanzelka, M. R. Parsek, and E. P. Greenberg. Detection, purification, and structural elucidation of the acylhomoserine lactone inducer of Vibrio fischeri luminescence and other related molecules. Bioluminescence and Chemiluminescence, Pt C, 305:288-301, 2000. |





Contact
Address: Celestijnenlaan 200G room 00.08 - 3001 Heverlee
Telephone: +32(0)16 32 73 19
Email: igem@chem.kuleuven.be






